Run a script on a GPU with one line of code¶
GPUs are powerful but only have an impact when they’re easy to use
GPUs can provide impressive performance boosts for certain workflows like training ML models, computer vision, analytics, and more. However GPU hardware can also be difficult to access and set up properly.
Here we show how to run a Python script on a GPU-enabled cloud machine with one line of code from your laptop.
$ coiled run --gpu python train.py
Example: Train a GPU-accelerated PyTorch model¶
Let’s train a GPU-accelerated PyTorch neural network on the CIFAR10 dataset. To start we’ll install the packages we need:
$ conda create -n pytorch -c conda-forge python=3.11 pytorch torchvision coiled
$ conda activate pytorch
$ pip install torch torchvision coiled
Next, we’ll save the PyTorch code below in a train.py Python script.
# train.py
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms
transform = transforms.Compose(
[
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2470, 0.2435, 0.2616)),
]
)
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(3, 2_500, 5)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(2_500, 16, 5)
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = x.view(-1, 16 * 5 * 5)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
# Select what hardware to use
if torch.cuda.is_available():
device = torch.device("cuda:0") # NVIDIA GPU
elif torch.backends.mps.is_available():
device = torch.device("mps") # Apple silicon GPU
else:
device = torch.device("cpu") # CPU
print(f"{device = }")
net = Net()
net = net.to(device)
trainset = torchvision.datasets.CIFAR10(
root="./data",
train=True,
download=True,
transform=transform,
)
trainloader = torch.utils.data.DataLoader(
trainset,
batch_size=400,
shuffle=True,
)
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)
# Train model on 10 passes over the data
for epoch in range(10):
print(f"Epoch {epoch}")
for i, data in enumerate(trainloader, 0):
inputs = data[0].to(device)
labels = data[1].to(device)
optimizer.zero_grad()
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
Note that PyTorch makes it straightforward to use different kinds of accelerated hardware. This portion of train.py:
# Select local hardware device to use
if torch.cuda.is_available():
device = torch.device("cuda:0") # NVIDIA GPU
elif torch.backends.mps.is_available():
device = torch.device("mps") # Apple silicon GPU
else:
device = torch.device("cpu") # CPU
tells PyTorch to run on an NVIDIA GPU, Apple silicon GPU, or traditional CPU, in that order, depending on what’s available locally where the code run.
When run on a Macbook Pro CPU, this script takes ~6.8 hours to run. When run on an Apple M1 GPU that time is reduced to ~1.4 hours (factor of ~4.9x speedup). From the same Macbook Pro we can run the training script on an NVIDIA GPU on a cloud VM using the following Coiled Run command:
$ coiled run --gpu python train.py
Under the hood, coiled run handles:
Provisioning a cloud VM with GPU hardware. In this case a
g4dn.xlarge(Tesla T4) instance on AWS.Setting up the appropriate NVIDIA drivers, CUDA runtime, etc.
Automatically installing the same packages I have locally on the cloud VM.
Making sure to install the CUDA-compiled version of PyTorch on the cloud VM.
Running
python train.pyon the cloud VM.
Our coiled run command takes ~14.1 minutes to complete, costs $0.12, and we have good GPU hardware utilization.
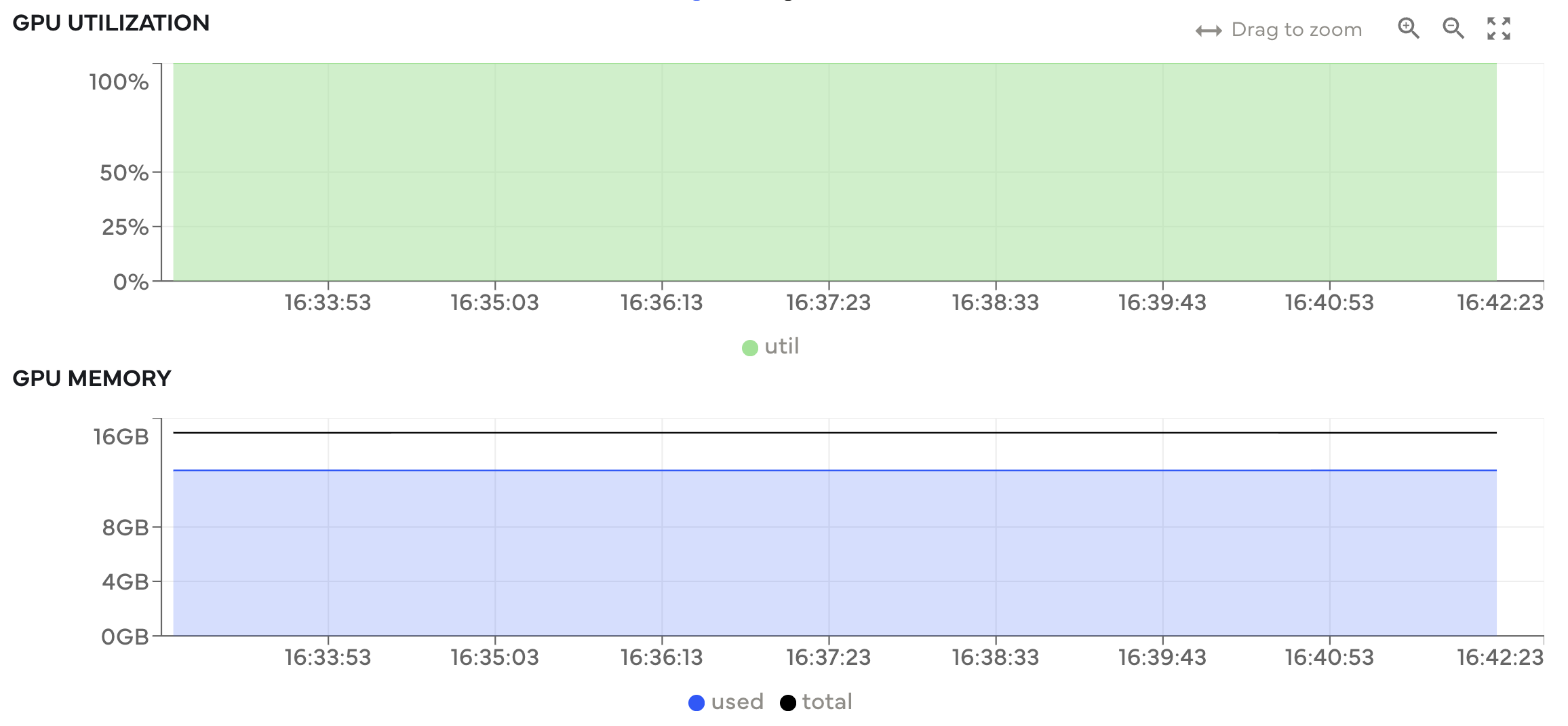
GPU utilization and memory usage. Both are near their maximum capacity, meaning we’re utilizing the available hardware well.¶
We spend ~4.7 minutes requesting, provisioning, and setting up the cloud VM, and ~9.8 minutes running the script. That’s a ~6x and ~29x overall speedup (including VM startup time) over the Apple silicon and CPU cases, respectively. Model training is ~8.6x and ~42x faster on the NVIDIA T4 GPU than on Apple silicon and CPU, respectively.

Comparing duration for running the same PyTorch training script on a CPU, Apple silicon GPU, and NVIDIA T4 GPU.¶
As we can see, PyTorch and Coiled complement each other well here. PyTorch handles using hardware that’s available locally, and Coiled handles running code on advanced hardware on the cloud. What’s nice here is one doesn’t really need to think about cloud devops or GPU software environment management to train a model on the GPU of their choosing. One can develop locally and, when needed, easily scale out to a GPU on the cloud.
Extend as needed¶
coiled run works well out of the box for common use cases, but also accommodates more complex situations like:
Larger GPU: Use
--vm-typeto run on any instance type available from your cloud providerCloud-hosted data: Use
--regionto run in the same region as your dataComplex software: Use
--containerto use a custom Docker containerWarm start: Use
--keepaliveto keep VMs up for a given amount of time for quick reuseInteractive use: Use
--interactive bashto be dropped into a terminal on your cloud VM
For example, running an LLM fine-tuning script might look something like:
$ coiled run \
--vm-type p4d.24xlarge \ # 8 A100 GPU node
--region us-west-2 \ # Same region as my data
--container huggingface/transformers-pytorch-gpu \ # Use this Docker image
python fine_tune.py
Summary¶
We showed how to use coiled run to run a PyTorch script on a cloud GPU. This was:
Easy: Run scripts on a GPU with one line of code
Fast: Get benefits of GPU acceleration without any devops work
Extensible: Extend
coiled runto match your specific use case
We hope the approach discussed here helps reduce friction in GPU workloads and can be copied / adapted for your own use case.
Here are additional GPU examples where some of the same Coiled features discussed here are also used: