Easy Scalable Production ETL#
We show a lightweight scalable data pipeline that runs large Python jobs on a schedule on the cloud.
Data |
Cost |
|---|---|
575 million records / day |
$10/day |
It’s common to run regular large-scale Python jobs on the cloud as part of production data pipelines. Modern workflow orchestration systems like Prefect, Dagster, Airflow, Argo, etc. all work well for running jobs on a regular cadence, but we often see groups struggle with complexity around cloud infrastructure and lack of scalability.
Here we show a scalable data pipeline that runs regular jobs on the cloud with Coiled and Prefect. The pipeline consists of a few Python files in this GitHub repository which you can run yourself either locally or on the cloud. This approach is:
Easy to deploy on the cloud
Scalable across many cloud machines
Cheap to run on ephemeral VMs and a small always-on VM
Defining tasks and cloud hardware in Python makes it easy for Python data developers to write and deploy their processing code quickly.
import coiled
from prefect import task, flow
import pandas as pd
@task
@coiled.function(region="us-east-2", memory="64 GiB") # <--- Define hardware in script
def json_to_parquet(filename):
df = pd.read_json(filename) # <--- Use simple pandas functions
df.to_parquet(OUTDIR / filename.with_suffix(".parquet").name)
@flow
def convert_all_files():
files = list_files()
json_to_parquet.map(files) # <--- Map across many files at once
Prefect runs Python jobs on a regular cadence. Coiled deploys Prefect on a cheap, always-on t3.medium instance (~$1/day) on AWS.
from datetime import timedelta
from prefect import serve
preprocess = json_to_parquet.to_deployment(
name="preprocess",
interval=timedelta(minutes=15), # <--- Run job on a regular schedule
)
reduce = query_reduce.to_deployment(
name="reduce",
interval=timedelta(hours=24), # <--- Different jobs at different schedules
)
...
serve(data, preprocess, reduce, ...)
Coiled creates on-demand Dask clusters for processing larger-than-memory datasets. This lets you scale out when you need to and only pay for hardware while you’re using it.
import coiled
from prefect import task, flow
import dask.dataframe as dd
@task
def unshipped_orders_by_revenue(bucket):
with coiled.Cluster(
n_workers=200, # <--- Ask for hundreds of workers
region="us-west-2", # <--- Run anywhere on any hardware
) as cluster:
with cluster.get_client() as client:
df = dd.read_parquet(bucket)
result = ... # Complex query
result.to_parquet(...)
Data pipelines#
How do I process large-scale data continuously in production?
While details will vary across use cases, data pipelines typically look something like:
Step 1: Acquire raw data from the real world
Example: A customer buys a loaf of bread at your grocery store
Example: A satellite measurements sea temperature in Antarctica
Step 2: Regularly process that raw data
Example: Apply data quality cuts followed by a feature engineering step
Example: Convert to a different storage format
Extra requirement: Retry on failures, run close to data in the cloud, alert me if processing fails
Step 3: Scalably analyze that data periodically
Example: Large-scale query of your data that addresses a business question
Example: Train an ML model for weather forecasting
Extra requirement: Data is too large to fit on a single machine
Step 4: Publish results
Example: Serve an interactive dashboard with a real-time view of customer orders
Example: Host an ML model
Running these steps on a regular cadence, task retries, and alerts are all handled well by modern workflow management systems like Prefect, Dagster, Airflow, Argo, etc. Managing cloud infrastructure and scalability is where most people tend to struggle.
Pain points of common data pipelines#
Pipelines can be overly complex or lack scalability.
Workflow management systems tend to struggle with:
Complexity around managing cloud infrastructure:
Provisioning / deprovisioning cloud machines
Software environment management
Handling cloud data access
Cost monitoring and spending limits
Scale limitations:
Scaling existing Python code across many cloud machines in parallel
Computing on larger-than-memory datasets (e.g. 100 TB Parquet dataset in S3)
Because of these issues, it’s common for systems to be overly complex or expensive. Below we show an example that connects Prefect and Coiled to run a lightweight, scalable data pipeline on the cloud.
Easy deployment for data pipelines#
Coiled and Prefect make it easy to run regularly scheduled jobs on the cloud at scale.
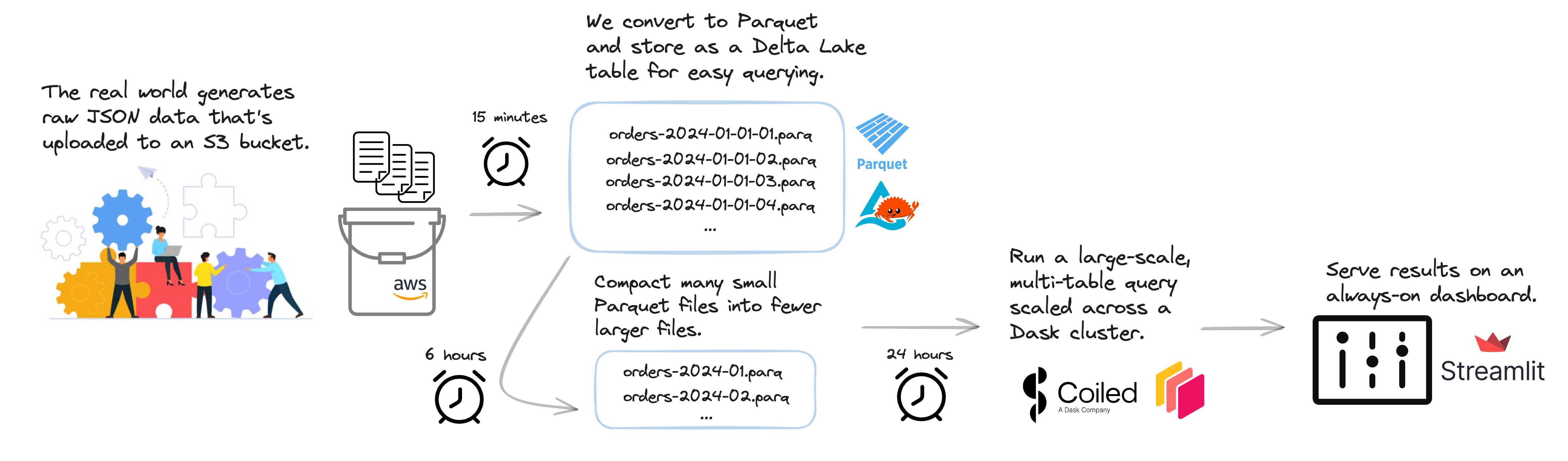
Coiled is a lightweight tool that makes deploying and scaling data pipelines on the cloud straightforward. This example data pipeline combines Coiled and Prefect to run regularly scheduled jobs on the cloud. It looks like this:
Step 1: Data generation – New TPC-H JSON files with customer orders and supplier information appear in an S3 bucket (every 15 minutes)
Step 2: Regular processing
JSON gets transformed into Parquet / Delta (every 15 minutes)
Data compaction of small Parquet files into larger ones for efficient downstream usage (every 6 hours)
Step 3: Scalable analysis – Run large-scale multi-table analysis query to monitor unshipped, high-revenue orders (every 24 hours)
Step 4: Serve dashboard – Results from latest business query are served on a dashboard (always on)
This pipeline processes ~575 million records daily and costs ~$10/day to run on the cloud. Let’s look at how Coiled and Prefect work together to this work.
Define tasks and hardware in Python#
Data-intensive Prefect tasks are common for per-file preprocessing steps, like those in pipeline/preprocess.py. We combine them with Coiled Functions for remote execution on cloud VMs. Defining tasks and cloud hardware in Python makes it easy for Python data developers to write and deploy their code quickly.
# pipeline/preprocess.py
import coiled
from prefect import task, flow
import pandas as pd
@task
@coiled.function(
region="us-east-2", # <-- Define hardware in script
memory="64 GiB",
)
def json_to_parquet(filename):
df = pd.read_json(filename) # <-- Use simple pandas functions
df.to_parquet(OUTDIR / filename.with_suffix(".parquet").name)
@flow
def convert_all_files():
files = list_files()
json_to_parquet.map(files) # <-- Run across many files at once
Run jobs regularly#
Related tasks are connected in a Prefect flow which defines their dependency to each other. This flow can then be scheduled to run regularly at different cadences, see for example in workflow.py.
We deploy this workflow on a cheap, always-on t3.medium instance (~$1/day) using Coiled’s coiled prefect serve CLI.
# workflow.py
from datetime import timedelta
from prefect import serve
preprocess = json_to_parquet.to_deployment(
name="preprocess",
interval=timedelta(minutes=15), # <--- Run job on a regular schedule
)
reduce = query_reduce.to_deployment(
name="reduce",
interval=timedelta(hours=24), # <--- Different jobs at different schedules
)
...
serve(data, preprocess, reduce, ...)
Scale with Dask clusters#
The large-scale, multi-table analysis query in pipeline/reduce.py uses Coiled to create an on-demand Dask cluster to handle processing our larger-than-memory data. Once the query is done all the VMs in the cluster are automatically shut down.
# pipeline/reduce.py
import coiled
from prefect import task, flow
import dask.dataframe as dd
@task
def unshipped_orders_by_revenue(bucket):
with coiled.Cluster(
n_workers=200, # <--- Ask for hundreds of workers
region="us-west-2", # <--- Run anywhere on any hardware
) as cluster, cluster.get_client() as client:
df = dd.read_parquet(bucket)
result = ... # Complex query
result.to_parquet(...)
Summary#
Data pipelines with regular large-scale Python jobs are common, but can be difficult to deploy on the cloud or don’t scale well. We showed how to:
Use Python for defining tasks and cloud hardware
Run jobs regularly on the cloud using Prefect and
coiled prefect serveScale with Dask when processing large volumes of data
in a scalable example data pipeline that processes ~575 million records daily and costs ~$10/day to run on the cloud.
Next steps#
You can run this example data pipeline yourself, either locally or on the cloud.
To run things locally, make sure you have a Prefect cloud account and have authenticated your local machine. Then clone the pipeline GitHub repo, install dependencies, and run the pipeline:
# Run data pipeline locally
git clone https://github.com/coiled/etl-tpch
cd etl-tpch
mamba env create -f environment.yml
mamba activate etl-tpch
python workflow.py
To run the same pipeline on the cloud, follow these instructions. Running the pipeline for several days fits comfortably within the Coiled free tier. We hope this example is easy to copy and modify for your needs.
You might also be interested in these additional use cases: