Dask, Dagster, and Coiled for Production Analysis at OnlineApp#
tl;dr#
We show a simple integration between Dagster and Dask+Coiled. We discuss how this made a common problem, processing a large set of files every month, really easy.

The User and the Problem#
Olá 👋 I’m Lucas, the data science tech lead at OnlineApp, a B2B company serving the Brazilian market.
Every month, the Brazilian government publishes a large set of CSV files with information on Brazilian companies that we use to better understand our market. We have lots of services that want to read this data, but before that’s possible we need to pre-process the data a bit:
Filter out some rows and columns that aren’t of interest to us;
Clean some values in several columns;
Join against other internal datasets we have;
Convert to Parquet and store in our own S3 storage;
We have many other services in our company that then rely on this data.
Architecture#
For regular jobs like this that run every month, we typically use Dagster. We like Dagster because it’s easy to use and feels natural. This runs on a VM in the cloud, so we have fast access to other cloud data (like these CSV files).
Normally, we would use pandas for this kind of work, but this set of files is too large to fit into memory (around ≅150 million rows with several columns), so we switched to Dask. Unfortunately, the dataset is also too large for our VM running Dagster, so we use Coiled to ask for a cluster of larger machines, each with a fair amount of memory.
In principle, we want to do something like this:
import coiled
import dask.dataframe as dd
from dagster import op
@op
def run_operation(context):
'''Processes all CSV files and saves the result as Parquet.'''
cluster = coiled.Cluster(
region="sa-east-1",
memory="64 GiB",
n_workers=100,
... # any other configuration options you need
)
client = cluster.get_client()
df = dd.read_csv("...")
... # custom code specific to our problem
df_result.to_parquet("...")
This would work, but we wanted to make this more natural by integrating it with Dagster. We’re excited to share what we did. It wasn’t a lot of code and resulted in a smooth experience.
Dagster + Coiled Integration#
Dagster has the concept of a Resource. Resources typically model external components that Assets and Ops (short for “Operations”, like in the example above) interact with. For example, a resource might be a connection to a data warehouse like Snowflake or a service like a REST API.
To make Dask+Coiled’s resources more reusable and also take advantage of all the extra functionality that Dagster provides when working with resources (more on that later), we transformed our Coiled cluster into a Dagster resource. This is straightforward to do:
from contextlib import contextmanager
from dagster import resource
import coiled
@resource(
config_schema={
"n_workers": int,
"worker_memory": str
}
)
@contextmanager
def dask_coiled_cluster_resource(context):
'''Yields a Dask cluster client.'''
with coiled.Cluster(
name=f"dagster-dask-cluster-{context.run_id}",
n_workers=context.resource_config["n_workers"],
worker_memory=context.resource_config["worker_memory"],
region="sa-east-1", # use your preferred region
compute_purchase_option="spot_with_fallback", # save money with spot
) as cluster:
with cluster.get_client() as client:
context.log.info(
f"Cluster created, dashboard link: {client.dashboard_link}"
)
yield client
To use this resource we add it to our job definition:
from dagster import job
@job(
resource_defs={
"dask_cluster": dask_coiled_cluster_resource,
},
config={
"resources": {
"dask_cluster": {
# set default values, but you can change these
# in the Dagster UI or later in the code
"config": {
"n_workers": 5,
"worker_memory": "64GiB"
},
},
},
}
)
def my_job():
'''My job DAGs definition.'''
...
result = my_op()
...
And finally, in the operations that need to have a Dask cluster to run computations, we inform these dependencies as follows:
from dagster import op
@op(
# specify the resource key that you want to use in this op
required_resource_keys={"dask_cluster"}
)
def my_op(context):
'''Run my computation with a Dask cluster.'''
# every computation inside this op will be executed with the Dask cluster
...
# we can also access and use our cluster client directly
context.resources.dask_cluster("...")
And that’s it, we now have full integration between Dagster, Dask and Coiled. Very easy to set up and maintain.
As a bonus, this is how we define a local Dask cluster for development and testing purposes:
from dagster import resource
from contextlib import contextmanager
from dask.distributed import Client, LocalCluster
@resource
@contextmanager
def dask_local_cluster_resource(context):
'''Yields a local Dask cluster client.'''
with LocalCluster() as cluster:
with cluster.get_client() as client:
context.log.info(
f"Cluster created, dashboard link: {client.dashboard_link}"
)
yield client
Results#
We now have nodes in our Dagster graph that are annotated as Dask+Coiled nodes. When Dagster runs these, they fire up a temporary Dask cluster, do larger scale processing than our Dagster VM can handle, and then clean up.
This image shows how the operation resource is listed in the Dagster UI:
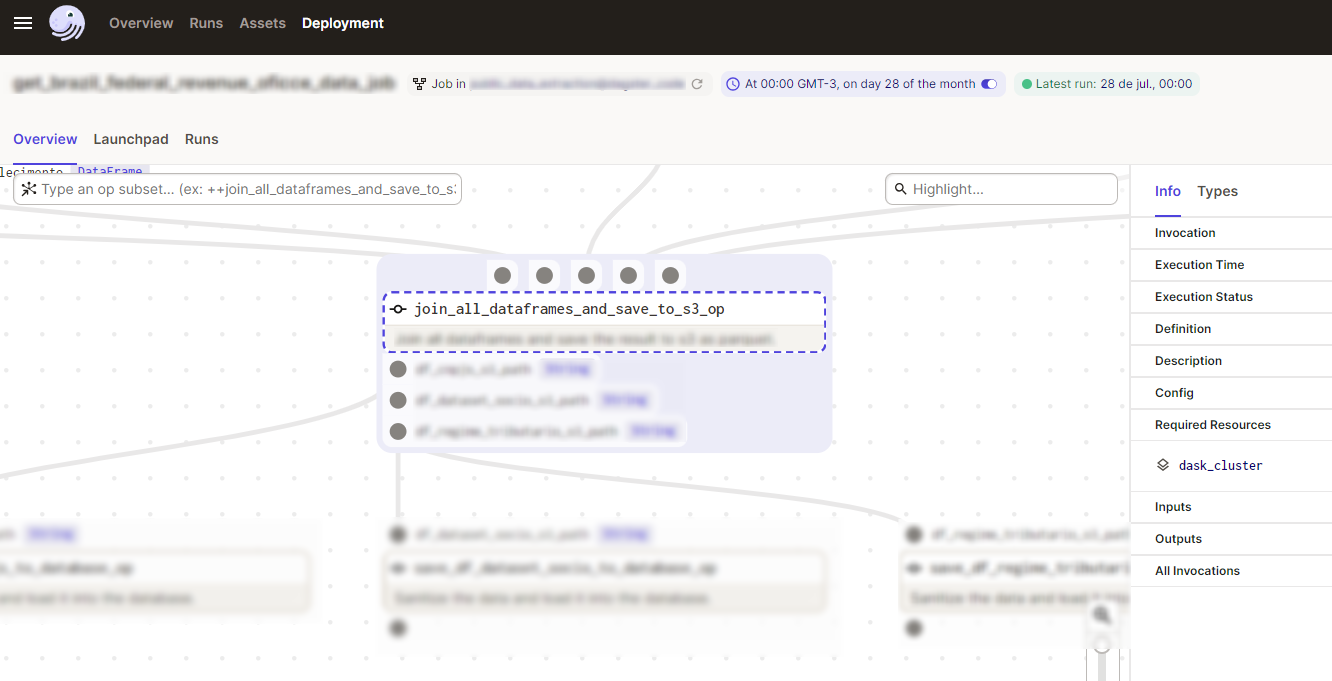
(Click to enlarge)#
And this is the Dagster Launchpad, here we can change several configurations before running our job, and one of those, thanks to defining our Coiled cluster as a resource, is choosing our cluster size, in a simple and parameterized way:
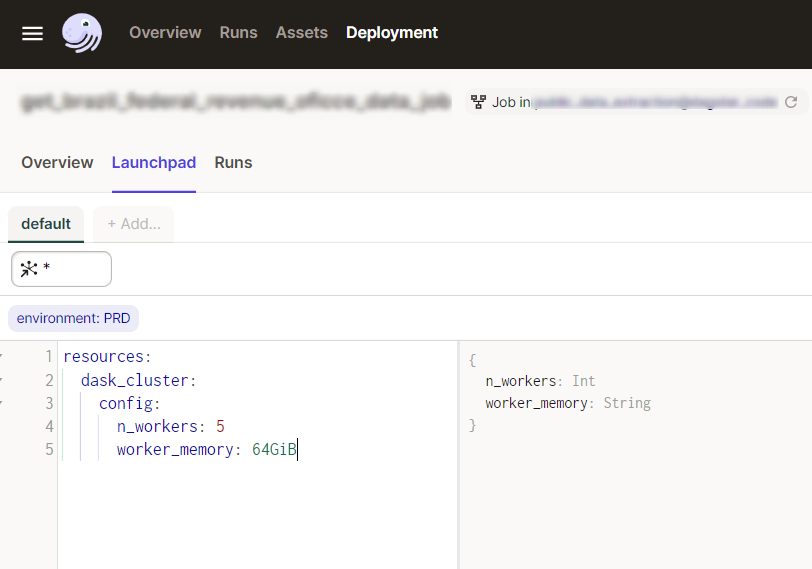
We’re now able to use our existing infrastructure to handle much larger datasets than we were able to use previously. Everything was very easy and cheap.
In Conclusion#
In this post we walked through an example of how to use Dagster and Dask+Coiled to orchestrate a recurring monthly data processing workflow. With Dask and Coiled, we were able to process the data in parallel using a cluster of VMs in the cloud. Dagster is able to take advantage of these cloud resources, enabling us to process much larger datasets than we otherwise could have.
We hope others looking to scale their Dagster workflows to the cloud will find this guide useful. For more resources on getting started with Coiled, check out our getting started guide.