Sep 9, 2024
3m read
Large Scale Geospatial Benchmarks#
TL;DR: We need your help creating a geospatial benchmark suite. Please propose your workload on this GitHub discussion.
People love the Xarray/Dask/… software stack for geospatial workloads, but only up to about the terabyte scale. At the terabyte scale this stack can struggle, requiring expertise to work well and frustrating users and developers alike.
To address this, we want to build a large-scale geospatial benchmark suite of end-to-end examples to ensure that these tools operate smoothly up to the 100-TB scale.
We need your help.
Benchmarks#
Dask developers have addressed similar issues of robust performance at scale for dataframes and tabular use cases by running existing industry standard benchmarks (see TPC-H benchmarks). Having these representative workloads was invaluable and enabled us to improve Dask DataFrame with much greater confidence.
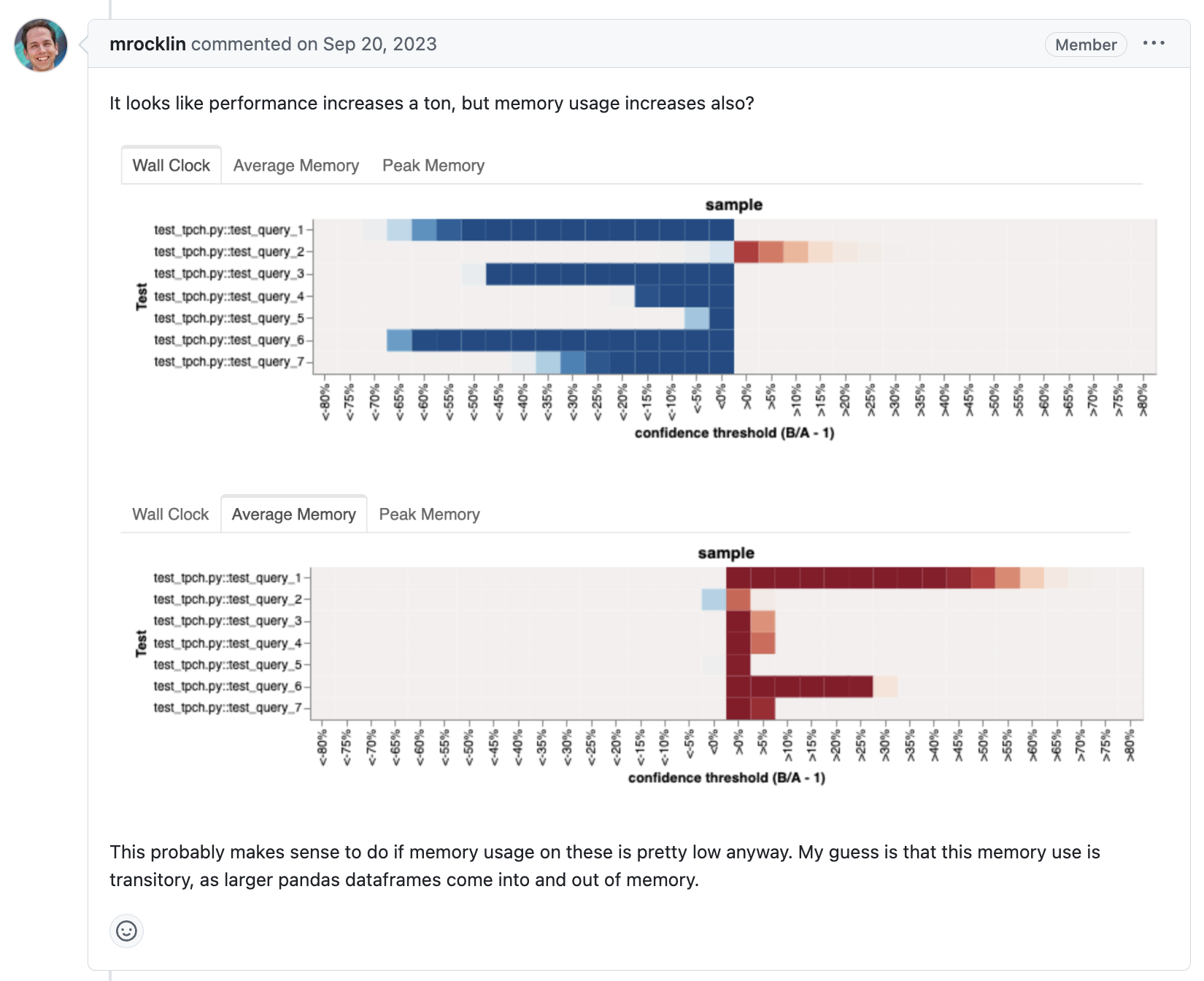
GitHub comment with A/B test results for a Dask update on TPC-H benchmark performance.#
This process has led to Dask DataFrame experiencing an average of 20x performance improvements at scale over the last year, which has been transformative to DataFrame users.
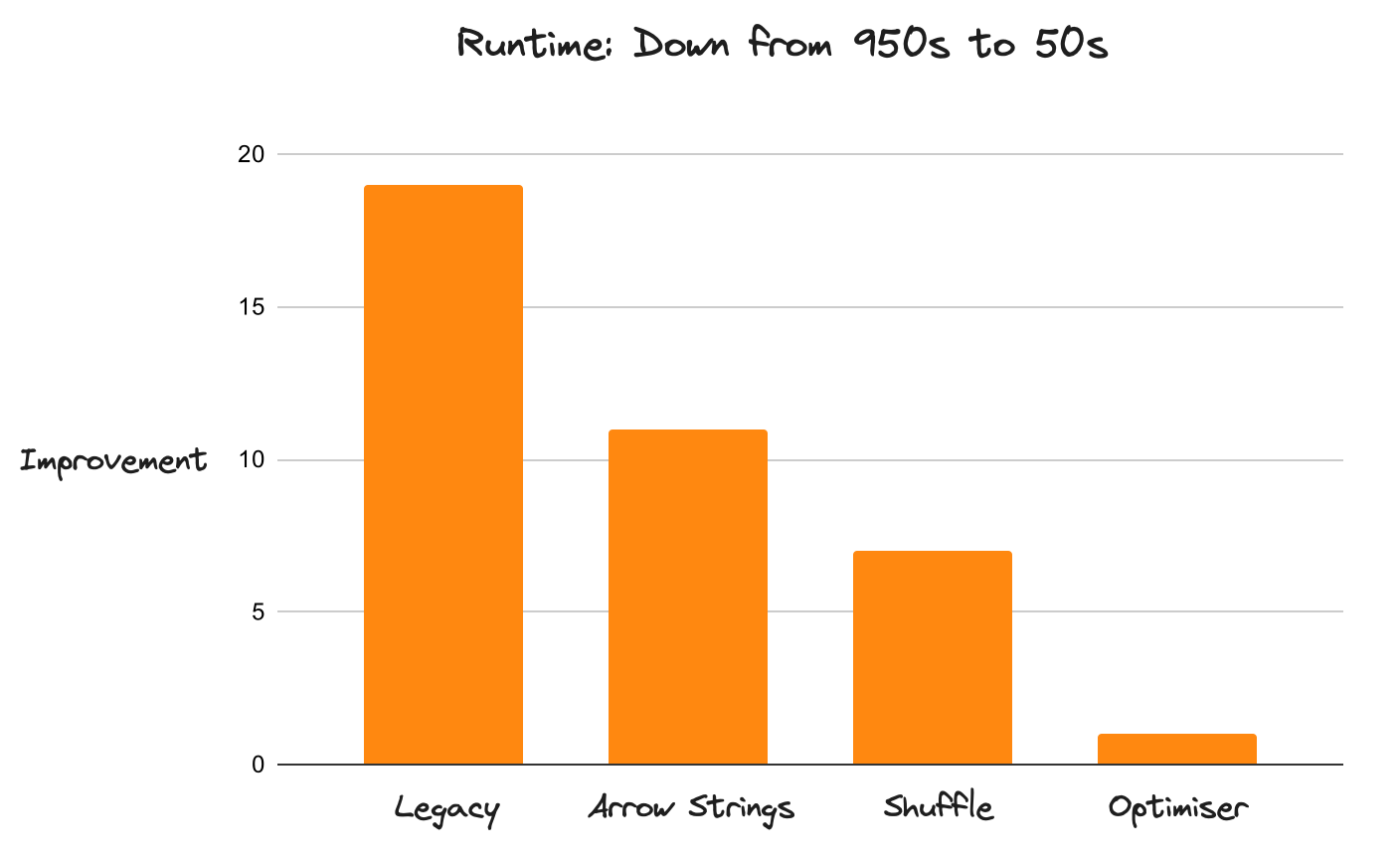
Performance improvements for Dask DataFrames#
Over the last month we’ve shifted focus to arrays, particularly supporting Xarray geospatial users, in hopes of getting similar speedups and robustness at large scale. To aid in this endeavor, we’d like to develop a similar suite of large-scale, representative geospatial workflows, and we’d like your help.
The rest of this post will go through what we’re looking for.
What makes a good benchmark#
There are many kinds of benchmarks ranging from microbenchmarks like the following:
%timeit x = np.random.random(...).mean()
to full, end-to-end benchmarks like the TPC-H benchmark suite:
import dask.dataframe as dd
date1 = datetime.strptime("2024-10-01", "%Y-%m-%d")
date2 = datetime.strptime("2024-07-01", "%Y-%m-%d")
line_item_ds = dd.read_parquet(dataset_path + "lineitem")
orders_ds = dd.read_parquet(dataset_path + "orders")
lsel = line_item_ds.l_commitdate < line_item_ds.l_receiptdate
osel = (orders_ds.o_orderdate < date1) & (orders_ds.o_orderdate >= date2)
flineitem = line_item_ds[lsel]
forders = orders_ds[osel]
jn = forders.merge(
flineitem, how="leftsemi", left_on="o_orderkey", right_on="l_orderkey"
)
result = (
jn.groupby("o_orderpriority")
.size()
.to_frame("order_count")
.reset_index()
.sort_values(["o_orderpriority"])
)
We’ve learned that microbenchmarks, or even normal-sized benchmarks, don’t provide the same high-quality direction that full end-to-end benchmarks provide. Historically we’ve done benchmarks that focused on specific parts of a workflow like rechunking, aggregations, slicing, and so on. However, while these simple benchmarks help us to accelerate parts of the system, they end up not having that big of an effect overall (performance at scale ends up being less about doing one thing well, and much more about doing nothing poorly).
What was transformative about the TPC-H DataFrame benchmarks for us was that they covered all aspects of a computation at once, from data loading, to a sequence of complex calculations, to collecting and plotting results, putting everything into perspective. These holistic benchmarks focused us in surprising directions, and uncovered flaws we wouldn’t have thought to look for. For example we spent far more time working on data ingestion than we thought, uncovered complex interactions between seemingly unrelated operations, and spent far less time working on in-memory performance than we expected.
As well as being full end-to-end, we think that benchmarks should be…
Relatively simple and easy to understand without sacrificing fidelity (we want other users to look at these benchmarks and see their own applications reflected within them)
Comprehensive and cover the space fairly well
Moderately independent (we don’t want many of the same kind of workflow)
Big (we’re mostly focused on TB or larger computations today)
Initial ideas#
We have a couple of end-to-end examples today that we like:
We like that they operate on real data, that they’re large (250TB and 1TB, respectively), and that we’ve seen lots of people do similar things (we share these blogposts frequently).
Each has also helped point us towards important rough edges at large scale that we weren’t previously aware of, improving a variety of tools in the PyData ecosystem including Xarray, Dask, and s3fs.
We want your help#
We want your help to build a catalog of large scale, end-to-end, representative benchmarks. What does this help look like? We can use:
Ideas of what are the most common workflows in this space like: “People often need to take netCDF files that are generated hourly, rechunk them to be arranged spatially, and then update that dataset every day”.
Real datasets to work on. We want to work with real data, not fake data.
Real code that does it. We don’t know the space well enough to write like a user here.
This is a big ask, we know, but we hope that if a few people can contribute something meaningfully then we’ll be able to contribute code changes that accelerate those workflows (and others) considerably.
We’d welcome contributions as comments to this GitHub discussion.