Nov 12, 2024
6m read
Airflow, Dask, & Coiled: Adding Big Data Processing to Your Cloud Toolkit#
Summary#
In this article, we showcase how Coiled technology enabled our data engineering and analytics team at Siemens to tackle complex data processing challenges. For an internal customer, we needed to analyze a large dataset of training records for an employee learning platform. By seamlessly integrating with our existing Python code and allowing us to deploy scalable Dask clusters in the cloud, Coiled reduced our ETL execution time by over 80%. This optimization not only benefited our internal Siemens customers, but also expanded our own data engineering portfolio for future projects.
We run Airflow locally and use Coiled to easily start a remote Dask cluster on AWS.#
Background#
As a data engineering and analytics team that works mainly in AWS, we frequently look to expand our technical toolkit and the portfolio of services we offer our customers. Besides using AWS Lambda functions for small event driven tasks, such as file deliveries and ingestions, we recently migrated to Apache Airflow as our main ETL tool.
We typically use Airflow PythonOperators to connect to various systems and perform tasks in a designed ETL workflow called a DAG. These tasks could be fetching data, pulling that data into a pandas DataFrame, and then pushing that DataFrame to a target destination. For efficiency, we execute most of our heavy ETL logic (data cleansing, joins, aggregations, calculations, etc.) in SQL and rely on our databases to handle the manipulation of large datasets.
Recently, however, we encountered a project where we needed to use a fuzzy algorithm to identify patterns and correlations in a dataset of employee training records. This algorithm is too complex to perform using BI tools or SQL. We needed to execute our logic directly in Python using a specific library and the resources available in our Airflow environment. For simple logic and small to medium sized datasets, this would usually not be a problem. In this case, however, applying the algorithm to a large dataset was very time consuming. Even after provisioning additional resources to Airflow, our job took at least an hour.
This was not optimal for our customer. We needed a different solution for processing big data more efficiently.
AWS Glue vs. EMR vs. Coiled#
After consulting our wise mentor ChatGPT, we determined we had a few options. In AWS some popular services for processing big data include AWS Glue and Elastic MapReduce (EMR) with Apache Spark. After some research, we realized most of these solutions involved a steep learning curve: managing new infrastructure, and/or essentially completely rewriting our existing Python code. After ruling out these options, another solution caught our eye: Coiled. ChatGPT summarized Coiled as “a managed Dask service that allows you to deploy Dask clusters in the cloud without the need to manage the underlying infrastructure.”
Not worrying about infrastructure sounded enticing. But would we have to rewrite our Python code to work with the Dask library? We pressed ChatGPT again. It assured us that since Dask DataFrame mimics pandas, we could easily scale to large datasets with minimal code changes.
This sounded too good to be true. We could use Coiled without having to worry about managing infrastructure in AWS and we wouldn’t need to completely rewrite our existing code. If this characterization of Coiled was accurate, we worried this could be expensive. Luckily, Coiled provides a free tier that was enough to cover our needs.
Getting started with Coiled#
We decided to give Coiled a shot.
We began by connecting our AWS account to Coiled. The setup in our AWS environment was simple; Coiled offers a link to CloudFormation to create a preformatted stack of the resources. This stack now allowed Coiled to create Dask clusters on our behalf. We then generated a new API token for authorizing our Airflow environment.
Creating the Coiled Software Environment#
When you start a Coiled cluster and do not specify any packages, the Coiled environment mirrors the library versions that exist in your local environment by default. It’s easier and faster than using Docker, and meant that we didn’t have to worry about Python package versions.
Authentication#
To authenticate Coiled from Airflow, we set the Coiled token with dask.config.set({"coiled.token": <our-token>}). We also set the AWS_ACCESS_KEY_ID, and AWS_SECRET_ACCESS_KEY environment variables to allow Coiled to interact with AWS resources on our behalf.
Coiled Cluster#
Starting the cluster is as easy as calling coiled.Cluster(), however, there are a number of customization options that allow us to tailor the cluster to our specific workload, optimizing both performance and cost. There are no standard rules here, so we tested different configurations to see how quickly our job ran using a varying number of workers and instance types in the cluster.
cluster = coiled.Cluster(
n_workers=10,
worker_vm_types=["c5.large"] # VM for compute-intensive workloads
)
client = cluster.get_client() # Connect to cluster
... # Dask computations
cluster.shutdown() # Cleanup resources
Once the cluster is set up, we connect to it. This connection is necessary to submit tasks and manage computations across the cluster. The client acts as a gateway between our Airflow environment and the distributed Dask workers.
Once all tasks are completed, we shutdown the cluster (Coiled will also do this automatically after 20 minutes of inactivity).
Putting it all together#
Once the cluster is up and running, we can execute our data processing logic on a Dask DataFrame, a parallelized version of pandas. After connecting to the cluster, we load our data into a Dask DataFrame and apply some group-by logic and the fuzzy algorithm to achieve our final dataset. The beauty of using Dask within this setup is that it automatically optimizes and distributes these operations across the cluster, making the processing highly efficient and easy to implement.
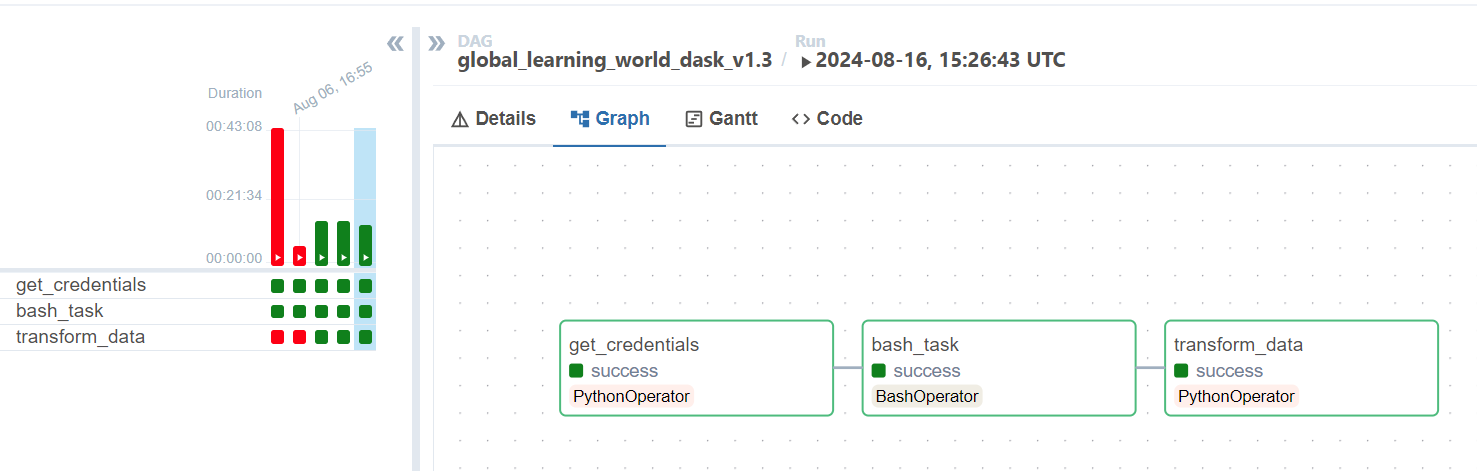
We used the Coiled UI to track a number of performance metrics and also keep track of uptimes, cloud costs, tasks processed, etc. During testing and set-up, we were regularly contacted by the Coiled team. They generously offered technical assistance and answered any questions we had. In one instance, the Dask library was updated in our Airflow environment, which caused a mismatch between Airflow and the Coiled software environment. A Coiled engineer promptly reached out after noticing our job had failed and pointed out the library discrepancies, which ultimately led to us using package sync to automatically handle the Python environment instead.
Conclusion#
The results of utilizing Coiled to run our job on a Dask cluster were remarkable. The execution time of our code shrank from over 1 hour to around 10 minutes, a reduction of over 80%. Our customer was thrilled, and our group was able to confidently add big data processing to our portfolio of data engineering services. If you are like us, passionate programmers who have little interest in slogging through cloud infrastructure, consider our use case. Forget outdated solutions like Apache Spark or low-code services like AWS Glue. Call in the big guns with a few lines of code. Use Coiled.