Oct 9, 2024
4m read
Scaling AI-Based Data Processing with Hugging Face + Dask#
This post was originally published on the Hugging Face blog.

The Hugging Face platform has many datasets and pre-trained models that make using and training state-of-the-art machine learning models increasingly accessible. However, it can be hard to scale AI tasks because AI datasets are often large (100s GBs to TBs) and using Hugging Face transformers for model inference can sometimes be computationally expensive.
Dask, a Python library for distributed computing, can handle out-of-core computing (processing data that doesn’t fit in memory) by breaking datasets into manageable chunks. This makes it easy to do things like:
Efficient data loading and preprocessing of TB-scale datasets with an easy to use API that mimics pandas
Parallel model inference (with the option of multi-node GPU inference)
In this post we show an example of data processing from the FineWeb dataset, using the FineWeb-Edu classifier to identify web pages with high educational value. We’ll show:
How to process 100 rows locally with pandas
Scaling to 211 million rows with Dask across multiple GPUs on the cloud
Processing 100 Rows with Pandas#
The FineWeb dataset consists of 15 trillion tokens of English web data from Common Crawl, a non-profit that hosts a public web crawl dataset updated monthly. This dataset is often used for a variety of tasks such as large language model training, classification, content filtering, and information retrieval across a variety of sectors.
It can take > 1 minute to download and read in a single file with pandas on a laptop.
import pandas as pd
df = pd.read_parquet(
"hf://datasets/HuggingFaceFW/fineweb/data/CC-MAIN-2024-10/000_00000.parquet"
)
Next, we’ll use the HF FineWeb-Edu classifier to judge the educational value of the web pages in our dataset. Web pages are ranked on a scale from 0 to 5, with 0 being not educational and 5 being highly educational. We can use pandas to do this on a smaller, 100-row subset of the data, which takes ~10 seconds on a M1 Mac with a GPU.
from transformers import pipeline
def compute_scores(texts):
import torch
# Select which hardware to use
if torch.cuda.is_available():
device = torch.device("cuda")
elif torch.backends.mps.is_available():
device = torch.device("mps")
else:
device = torch.device("cpu")
pipe = pipeline(
"text-classification",
model="HuggingFaceFW/fineweb-edu-classifier",
device=device
)
results = pipe(
texts.to_list(),
batch_size=25, # Choose batch size based on data size and hardware
padding="longest",
truncation=True,
function_to_apply="none"
)
return pd.Series([r["score"] for r in results])
df = df[:100]
min_edu_score = 3
df["edu-classifier-score"] = compute_scores(df.text)
df = df[df["edu-classifier-score"] >= min_edu_score]
Note that we also added a step to check the available hardware inside the compute_scores function, because it will be distributed when we scale with Dask in the next step. This makes it easy to go from testing locally on a single machine (either on a CPU or maybe you have a MacBook with an Apple silicon GPU) to distributing across multiple machines (like NVIDIA GPUs).
Scaling to 211 Million Rows with Dask#
The entire 2024 February/March crawl is 432 GB on disk, or ~715 GB in memory, split up across 250 Parquet files. Even on a machine with enough memory for the whole dataset, this would be prohibitively slow to do serially.
To scale up, we can use Dask DataFrame, which helps you process large tabular data by parallelizing pandas. It closely resembles the pandas API, making it easy to go from testing on a single dataset to scaling out to the full dataset. Dask works well with Parquet, the default format on Hugging Face datasets, to enable rich data types, efficient columnar filtering, and compression.
import dask.dataframe as dd
df = dd.read_parquet(
# Load the full dataset lazily with Dask
"hf://datasets/HuggingFaceFW/fineweb/data/CC-MAIN-2024-10/*.parquet"
)
We’ll apply the compute_scores function for text classification in parallel on our Dask DataFrame using map_partitions, which applies our function in parallel on each pandas DataFrame in the larger Dask DataFrame. The meta argument is specific to Dask, and indicates the data structure (column names and data types) of the output.
from transformers import pipeline
def compute_scores(texts):
import torch
# Select which hardware to use
if torch.cuda.is_available():
device = torch.device("cuda")
elif torch.backends.mps.is_available():
device = torch.device("mps")
else:
device = torch.device("cpu")
pipe = pipeline(
"text-classification",
model="HuggingFaceFW/fineweb-edu-classifier",
device=device,
)
results = pipe(
texts.to_list(),
batch_size=768,
padding="longest",
truncation=True,
function_to_apply="none",
)
return pd.Series([r["score"] for r in results])
min_edu_score = 3
df["edu-classifier-score"] = df.text.map_partitions(compute_scores, meta=pd.Series([0]))
df = df[df["edu-classifier-score"] >= min_edu_score]
Note that we’ve picked a batch_size that works well for this example, but you’ll likely want to customize this depending on the hardware, data, and model you’re using in your own workflows (see the HF docs on pipeline batching).
Now that we’ve identified the rows of the dataset we’re interested in, we can save the result for other downstream analyses. Dask DataFrame automatically supports distributed writing to Parquet. However, since Hugging Face uses commits to track dataset changes, we needed a custom function to allow writing a Dask DataFrame in parallel to Hugging Face storage.
from dask_hf import to_parquet
to_parquet(
df,
"hf://datasets/<your-hf-user>/<data-dir>" # Update with your dataset location
)
In the future, we’ll create a direct integration with Dask and huggingface_hub, but for now, you can copy + paste this custom function for your own use. In this example, we’ve saved it to a file called dask_hf.py, which is the file referenced in the import clause above.
Multi-GPU Parallel Model Inference#
There are a number of ways to deploy Dask on a variety of hardware. Here, we’ll use Coiled to deploy Dask on the cloud so we can spin up VMs as needed, and then clean them up when we’re done.
cluster = coiled.Cluster(
region="us-east-1", # Same region as data
n_workers=100,
spot_policy="spot_with_fallback", # Use spot instances, if available
worker_vm_types="g5.xlarge", # NVIDIA A10 Tensor Core GPU
worker_options={"nthreads": 1},
)
client = cluster.get_client()
Under the hood Coiled handles:
Provisioning cloud VMs with GPU hardware. In this case,
g5.xlargeinstances on AWS.Setting up the appropriate NVIDIA drivers, CUDA runtime, etc.
Automatically installing the same packages you have locally on the cloud VM with package sync. This includes Python files in your working directory, so we can import directly from
dask_hf.pyon the remote cluster.
The workflow took ~5 hours to complete and we had good GPU hardware utilization.
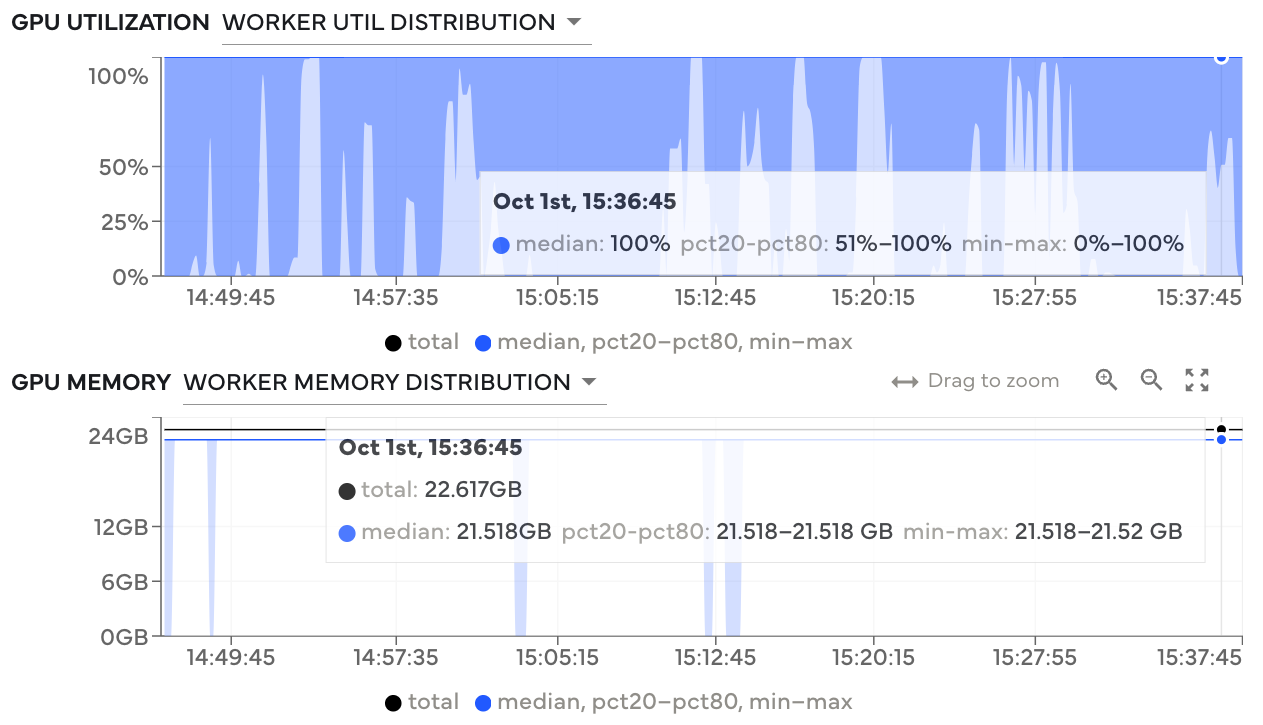
GPU utilization and memory usage are both near their maximum capacity, which means we’re utilizing the available hardware well.#
Putting it all together, here is the complete workflow:
import dask.dataframe as dd
from transformers import pipeline
from dask_hf import to_parquet
import os
import coiled
cluster = coiled.Cluster(
region="us-east-1",
n_workers=100,
spot_policy="spot_with_fallback",
worker_vm_types="g5.xlarge",
worker_options={"nthreads": 1},
)
client = cluster.get_client()
cluster.send_private_envs(
{"HF_TOKEN": "<your-hf-token>"} # Send credentials over encrypted connection
)
df = dd.read_parquet(
"hf://datasets/HuggingFaceFW/fineweb/data/CC-MAIN-2024-10/*.parquet"
)
def compute_scores(texts):
import torch
# Select which hardware to use
if torch.cuda.is_available():
device = torch.device("cuda")
elif torch.backends.mps.is_available():
device = torch.device("mps")
else:
device = torch.device("cpu")
pipe = pipeline(
"text-classification",
model="HuggingFaceFW/fineweb-edu-classifier",
device=device
)
results = pipe(
texts.to_list(),
batch_size=768,
padding="longest",
truncation=True,
function_to_apply="none"
)
return pd.Series([r["score"] for r in results])
min_edu_score = 3
df["edu-classifier-score"] = df.text.map_partitions(compute_scores, meta=pd.Series([0]))
df = df[df["edu-classifier-score"] >= min_edu_score]
to_parquet(
df,
"hf://datasets/<your-hf-user>/<data-dir>" # Replace with your HF user and directory
)
Conclusion#
Hugging Face + Dask is a powerful combination. In this example, we scaled up our classification task from 100 rows to 211 million rows by using Dask + Coiled to run the workflow in parallel across multiple GPUs on the cloud.
This same type of workflow can be used for other use cases like:
Filtering genomic data to select genes of interest
Extracting information from unstructured text and turning them into structured datasets
Cleaning text data scraped from the internet or Common Crawl
Running multimodal model inference to analyze large audio, image, or video datasets