Oct 20, 2025
4m read
MLflow on Coiled with Sidecars and Filestores#
Coiled lets you run ephemeral clusters in the cloud. We introduce sidecars to run arbitrary containers alongside your workload, and filestores to sync local data to the cloud and persist data across runs. We use them to run an MLflow server concurrently with model training.
MLflow is a widely used open source tool for ML experiment tracking, model packaging, registry management, and deployment. Some people host their own server, but many use a hosted solution. Our users asked us about running MLflow on Coiled, and, using some new features, we finally found a way that aligns with Coiled’s principle of only paying for what you use. It’s idiosyncratic, but it works quite well.
Running MLflow as a Sidecar#
It’s always been possible to run MLflow on Coiled using coiled run, but this required starting the server before training, obtaining the server’s URL, and passing it to the training code—too many moving parts.[1]
Instead, we introduce sidecars, a feature that lets you specify one or more Docker containers to run on the scheduler and/or workers during jobs. With them, you can run the MLflow server alongside the training code. We have no intention of going full Docker Compose on you, but you may recognize the format if you squint at a sidecar spec YAML file:
mlflow:
image: astral/uv:debian-slim
command: uvx mlflow server --host 0.0.0.0 --port 5000
ports:
- 5000
There’s a name for the sidecar, the image to use, the command to run, and any ports to expose. To launch MLflow, we use a small uv container and uvx instead of using the official MLflow image, like we did in the marimo post.
You can also define sidecars directly in your Python code. Here’s an example of adding a sidecar to a Dask cluster:
cluster = coiled.Cluster(
...,
scheduler_sidecars=[
{
"name": "mlflow",
"image": "astral/uv:debian-slim",
"command": "uvx mlflow server --host 0.0.0.0 --port 5000",
"ports": [5000]
}
]
)
Persisting Data with Filestores#
To persist data across jobs, we use filestores, a new feature that enables:
Copying data between your local machine and Coiled-managed VMs in the cloud,
Persisting it between multiple runs, and
Transferring data between steps in a processing pipeline.
Here’s a quick example of using a filestore with coiled batch to copy local files from local-directory to the cloud VM where my_script.py runs:
coiled batch run --sync local-directory --wait my_script.py
The files will be available in the workers’ working directory, and any outputs that the code writes to the working directory on the cloud VM will be stored in a filestore, available for download to the local machine or to other Coiled-managed cloud VMs. All tasks in a batch job share the filestore, and you can sync back outputs from all the tasks together to your local machine with:
coiled file download --into output-data
In the example above, we add the --wait flag to wait until work completes, and then sync new or modified files back to the local machine, instead of the default non-blocking behavior for coiled batch run.
The sidecar spec lets you specify filestores to attach. Data in named filestores are downloaded to the file:///scratch/filestores directory on the VMs. Here, we attach a filestore named mlflow-data to persist the MLflow backend data:
mlflow:
image: astral/uv:debian-slim
command: uvx --python 3.13 mlflow server --host 0.0.0.0 --port 5000
--backend-store-uri file:///scratch/filestores/mlflow-data
ports:
- 5000
filestores:
- name: mlflow-data
Training Code and Launching the Cluster#
With Coiled Batch, the training code doesn’t need to know anything about Coiled. That way, it can also run locally. Yet, we find it convenient to set a few # COILED comments in the header that Coiled will pick up, like:
# COILED env MLFLOW_TRACKING_URI=http://coiled-scheduler:5000
# COILED env MLFLOW_TRACKING_USERNAME=alex
# COILED gpu true
# COILED map-over-values 0.1, 0.05, 0.01
These comments:
Set the MLflow server’s URL as the scheduler’s address, now available as
http://coiled-scheduleron the workers (it’s still available as theCOILED_BATCH_SCHEDULER_ADDRESSenvironment variable too),Set the user name so it’s logged with the experiment results,
Request VMs with a GPU attached,
And specify the list of learning rates to try. Coiled will launch a VM for each value.
The model we train in the example is a straightforward PyTorch classifier on the FashionMNIST dataset and doesn’t contain any Coiled-specific code. The only notable thing is that it accepts the loss value as an argument, so we can train the model locally and on the cloud without modifying the code. You can run it locally with:
python train.py 0.1
Or in the cloud, with the MLflow sidecar alongside, with:
coiled batch run --scheduler-sidecar-spec mlflow-sidecar.yaml \
-- train.py \$COILED_BATCH_TASK_INPUT
While the cluster is running, you can access the MLflow server using the button on the cluster’s page:
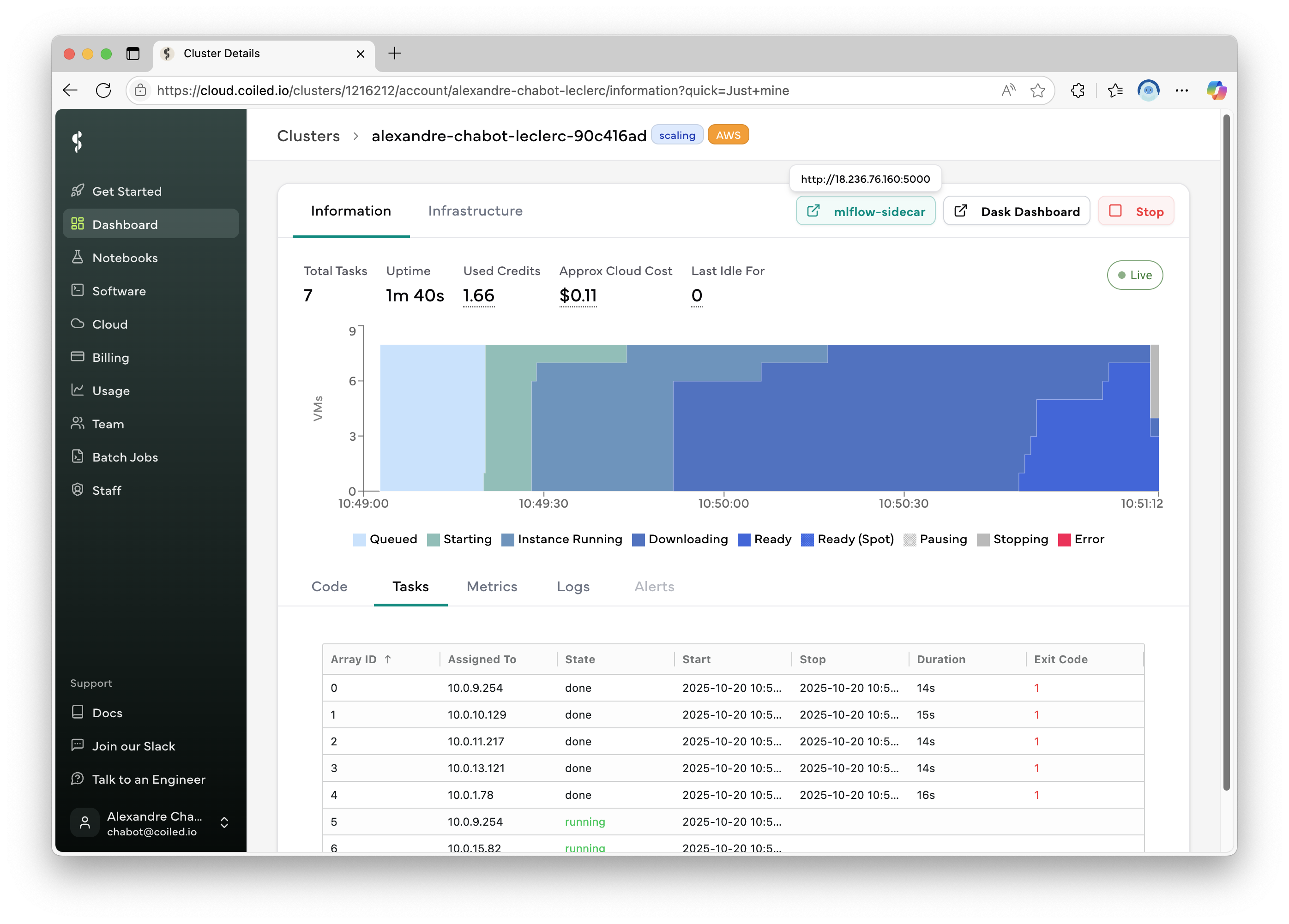
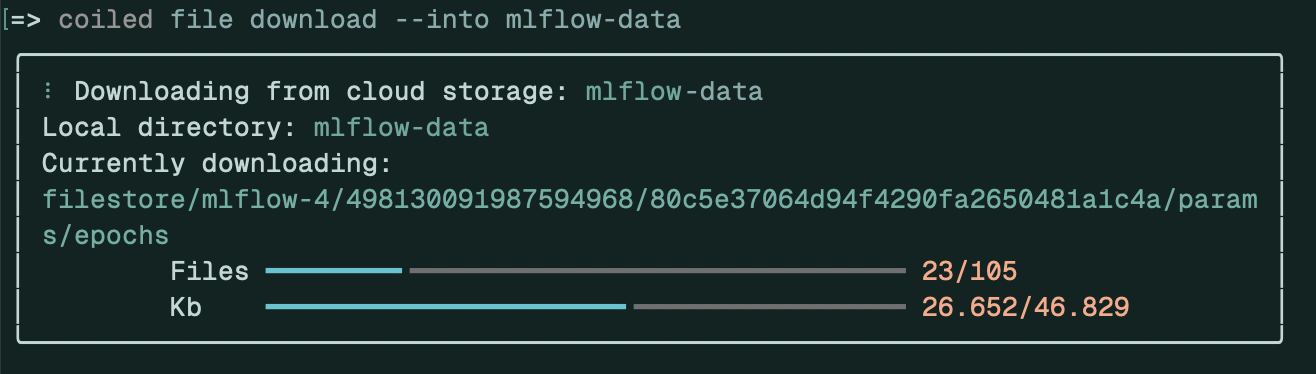
Once the cluster has stopped, you can download the filestore data to your computer with:
coiled file download --into mlflow-data
And start the MLflow server to browse the results:
mlflow server \
--backend-store-uri mlflow-data \
--artifacts-destination mlflow-data
Check out the complete MLflow example to learn how to browse MLflow data remotely and split the metadata and model data into separate filestores.
MLflow Is for Sharing#
To share MLflow data with other users, simply use the same filestore name. Because filestores share the same bucket for a given Coiled workspace in a given region, data is automatically available to all members of a workspace. The MLflow unique IDs ensure there are no collisions between experiments and runs.
What Else Can You Do With Sidecars and Filestores?#
Other than running MLflow, we know some users plan on using sidecars to run a proxy on each worker to make authorized, encrypted connections to databases.
As for filestores, they address a common request to make it easy to upload local files to clusters when using Coiled Batch. We think you’ll like them. Check out the filestore docs to learn more, and let us know what you think about them.