May 7, 2025
6m read
Python is annoying to run on EMR, but you have options#
Amazon EMR (Elastic MapReduce) is a powerful managed cluster platform that helps organizations process large amounts of data. While AWS EMR offers significant performance benefits, its cost structure is complex and and many teams fail to consider the additional cost of developer time and energy.
In this article, we’ll cover:
The main drivers of EMR cost
Why Python teams face additional challenges with EMR
Coiled as a Python-native alternative for data processing workloads
Though EMR can run distributed data processing jobs with a number of open source libraries, this post will primarily focus on running Apache Spark on EMR, as that is the most widely used.
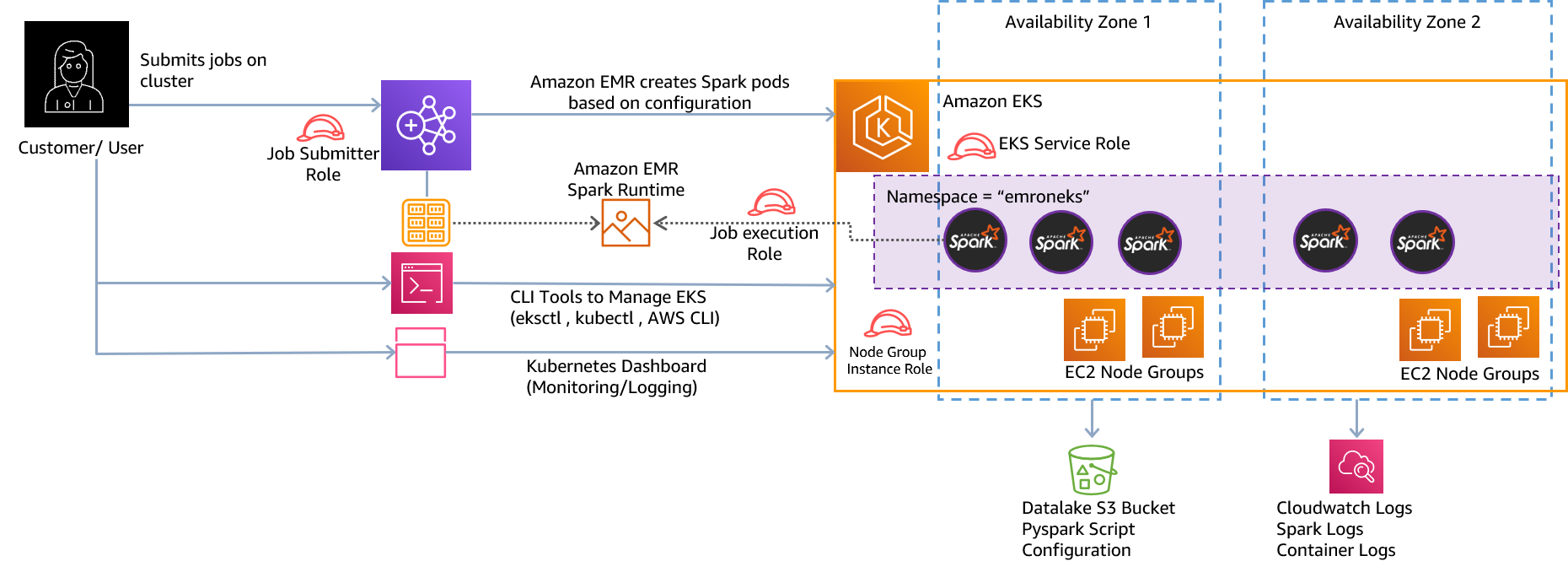
Architecture diagram of running an Apache Spark cluster on AWS EMR on EKS from the AWS Big Data Blog.#
AWS EMR costs broken down#
There are multiple factors to consider when assessing the prospective cost of AWS EMR for your analytics and data workloads. While AWS EMR uses a consumption-based pricing model, you’ll also need to factor in EC2 costs, storage, data transfer, and a number of additional hidden costs.
AWS EMR pricing model#
AWS EMR follows a “pay-as-you-go” consumption-based pricing model where users pay for the resources they consume. Pricing varies based on the deployment mode and instance type selected.
Primary EMR deployment options include:
EMR on EC2: Users pay for both the EC2 instances and EMR service fees.
EMR on EKS (Elastic Kubernetes Service): Costs are based on Kubernetes resources used, including EC2 instances or Fargate compute charges.
EMR Serverless: Users are billed based on the number of compute units and memory usage per second.
EC2 instance costs#
Since EMR clusters run on Amazon EC2 instances, compute costs are a significant portion of EMR expenses. Instance options include:
On-demand instances: Pay for compute capacity by the second, with no long-term commitments.
Burstable instances: Perfect for workloads like web servers which have low CPU utilization most of the time, but occasionally fully utilize the CPU.
Spot instances: Significant cost savings (up to 90%) by using spare AWS capacity, but they can be interrupted.
ARM instances: Using ARM (Graviton) instances can reduce costs for certain workloads, in some cases up to 50%.
Reserved instances: Provide discounts in exchange for committing to EC2 capacity for one to three years.
Storage and data transfer costs#
Storage and data transfer also contribute significantly to AWS EMR costs:
Amazon S3 storage: Many EMR workloads rely on Amazon S3 for data storage. Costs depend on the storage tier (standard, infrequent access, or glacier).
Amazon EBS (Elastic Block Store): If EC2 instances use attached EBS volumes, storage fees apply based on provisioned capacity.
Data transfer fees: Transferring data within the same AWS region is free, but inter-region and external data transfers incur additional charges.
EMR is also hard to use#
When evaluating AWS EMR, most organizations focus primarily on direct compute and storage costs, though there are significant hidden costs to consider:
1. Cluster management and DevOps overhead#
Unlike fully serverless solutions, AWS EMR requires ongoing management and tuning to maintain optimal performance. Key challenges include:
Provisioning and scaling clusters
Cluster lifecycle management
Monitoring and logging complexity
2. Engineering costs for Python-based data science teams#
For teams working primarily in Python, EMR introduces additional engineering overhead:
Tuning Spark performance (efficient memory allocation, partitioning, etc. require Spark expertise)
Inefficient debugging and development cycles (Spark clusters are notoriously time-consuming to debug)
PySpark serialization and rewriting code for Spark compatibility
3. Vendor lock-in risks#
Committing to AWS EMR can create dependencies on AWS-specific features and services, making it difficult to migrate workloads to other platforms in the future.
Coiled: A Python-native alternative to AWS EMR#
For teams working in Python, AWS EMR’s reliance on Spark and Hadoop adds unnecessary overhead, making development slower and more expensive. If you haven’t committed to EMR yet or want easier alternatives for new workloads, Coiled offers an alternative.
Why choose Coiled over AWS EMR?#
Coiled provides a modern, Python-native alternative that’s easy to use, highly scalable, and cost-effective.
1. Python-native#
Coiled is designed for Python data developers. For distributed computing Coiled leverages Dask, an open source parallel computing library. Dask feels a lot like pandas, making it easy for teams to scale their existing pandas code with minimal modifications.
EMR, by comparison, commonly relies on Spark for distributed computing. For data teams using primarily Python, migrating to Spark is notoriously challenging.
A lot of the Spark internals are run on the JVM, so it’s actually not that easy to debug. You spend a lot of time on Stack Overflow trying to figure out what did I do wrong, why am I getting this traceback. It was painful.
Sébastien Arnaud, CDO/CTO at Steppingblocks, on why they switched from Spark to Dask
Since Dask is just Python, you don’t have to waste time debugging JVM errors. Additionally, you can easily see metrics like CPU and memory utilization in the Coiled UI or detailed task-level progress with the Dask dashboard.
2. Zero infrastructure management#
Coiled eliminates cluster management overhead by automatically handling provisioning, scaling, and maintenance of AWS resources. This means you no longer need to:
Wait for Docker images or build custom AMIs. With Coiled, software is automatically replicated on your cloud VMs with package sync.
Rightsize Kubernetes. Coiled relies on a simpler architecture, automatically spinning up raw EC2 instances when you need them in ~ a minute.
Worry about VMs left on over the weekend. Coiled automatically turn things off when your computation is done and sends out alerts if things have been running longer than usual.
For teams without a dedicated cloud infrastructure team, this frees up key engineers from infrastructure overhead. Instead of spending their time figuring out why EKS isn’t working, they can focus on their area of expertise.
3. Cost savings#
The cloud can be quite cheap, ~$0.10 / TiB, if you’ve configured everything correctly. Coiled makes it easy to use the cloud at scale efficiently:
Auto-scaling based on workload demands
Trivial to use Spot, ARM
Read data in-region to avoid egress fees
Set team- and user-specific resource limits
Eliminate dead costs with auto-shutdown and clean-up once you’re done
There’s also a generous free tier of 500 CPU hours per month.
import coiled
cluster = coiled.Cluster(
n_workers=[10, 100], # Autoscale as needed
spot_policy="spot_with_fallback", # Use spot when available
arm=True, # Use ARM
region="us-west-2", # Same region as your data
)
4. No vendor lock-in#
Coiled works with AWS, GCP, or Azure. Access your data wherever it’s stored (Snowflake, S3, Azure Blob, etc.) and use the same libraries you’re already using (Polars, PyTorch, Xarray, even GDAL).
Read in Parquet files from S3 with your preferred DataFrame library (pandas, Polars, DuckDB, Dask, …) with Coiled’s serverless functions.
import polars as pl
import coiled
@coiled.function(memory="512 GiB")
def run_query():
df = (
pl.scan_parquet("s3://my-bucket/*")
.filter(pl.col("balance") > 0)
.group_by("account")
.agg(pl.all().sum())
)
return q.collect
With dask_snowflake, you can read from a Snowflake table into a Dask DataFrame.
import coiled
import dask_snowflake
cluster = coiled.Cluster(n_workers=50)
client = cluster.get_client()
example_query = """
SELECT *
FROM SNOWFLAKE_SAMPLE_DATA.TPCH_SF1.CUSTOMER;
"""
df = read_snowflake(
query=example_query,
connection_kwargs={
"user": "...",
"password": "...",
"account": "...",
},
)
When to still use EMR?#
EMR still has its place, especially in certain Spark-heavy environments. Here are some reasons why you might stick with EMR:
You’re deeply invested in Apache Spark
EMR is optimized for Spark, and if your team already has Spark pipelines, libraries, and infrastructure, migrating everything to Dask might be time consuming.
You need tight AWS service integration
If you’re already embedded into the AWS ecosystem and using tools like AWS Glue and Step Functions, EMR fits in naturally.
Your team already has EMR expertise
If your data team already knows how to wrangle EMR clusters, it’s hard to justify switching unless there’s a real gain in productivity or cost.
Getting started with Coiled#
It’s easy to get started with Coiled:
$ pip install coiled
$ coiled quickstart
Learn more: