Apr 4, 2023
8m read
Burstable vs non-burstable AWS instance types for data engineering workloads#
Nat Tabris
There are many instance types to choose from on AWS. In this post, we’ll look at one choice you can make—burstable vs non-burstable instances—and show how the “cheaper” burstable option can end up being more expensive for data engineering workloads.
AWS offers burstable EC2 instances with a lower base price than the corresponding non-burstable instance types.

Burstable instances are perfect for workloads like web servers which have low CPU utilization most of the time, but occasionally fully utilize the CPU—web traffic tends to be bursty.
What about data science/engineering workloads? For these use-cases, burstable instances are worse than we expected. For a wide-range of data workloads, non-burstable instances are both cheaper per hour and faster.
Coiled offers managed Dask in the cloud. Based on what we’ve learned about burstable instances, we’re changing the default Intel-based instance types on AWS from t3 to m6i instances. This is one of the many ways that we help users run Python at scale efficiently (as well as cheaply and securely).
In the rest of the post, we’ll see the impact on overall costs across our benchmark suite, and then dig into a few workloads to see how non-burstable instances provide better performance for CPU, disk, and network.
Overall Benchmark Costs#
Coiled runs a suite of Python/Dask benchmarks on AWS. This collection of ~100 benchmarks cover common data science, data engineering, and machine learning workloads. A typical run takes around 150 instance-hours (though as we’ll see, this depends on the choice of instance type).
When we switched from burstable to non-burstable instance types, we saw a significant reduction in cost. For instance, comparing two individual runs, we saw costs go from $7.13 (burstable) to $3.89 (non-burstable).

This cost difference is due to two things:
The burstable surcharge
Poor performance of burstable instances
We’ll go into more detail on each of these in the sections below.
Burstable surcharge#
If you take a look at the prices that AWS lists for EC2 instances (here’s the on-demand pricing), you’ll see that t3.large instances are cheaper than m6i.large instances. So why is the total cost for m6i.large so much lower?
With burstable instances, the base price covers CPU utilization up to some limit: 30% for t3.large, 40% for t3.xlarge and t3.2xlarge. This base price is about 15% cheaper than the price of the corresponding non-burstable instances.
With burstable instances there are two types of costs you need to watch: the base price, and the extra CPU credit cost. What’s this extra cost about?
Burstable t3.large instances have a “baseline” of 30% CPU utilization. When your utilization is lower, you accumulate CPU credits. When your utilization is higher, you use the credits you’ve accumulated, or if you don’t have enough credits, you pay extra.
In the case of our benchmark suite, these extra CPU credits were 28% of the total non-burstable compute cost and made our burstable compute significantly more expensive than non-burstable compute.
You can see these costs for yourself on instances in your account as explained in our blog post about AWS Cost Explorer.
More generally, using m6i.large instances are cheaper than t3.large instances when you have sustained CPU utilization above 42.5%. See this AWS doc for details about how this is calculated.
What if I only want to pay the base price, nothing extra? If you never want to pay for extra CPU credits, you can use “standard” rather than “unlimited” mode with burstable instances. In this case, instead of paying for CPU credits, your performance is throttled. While this may make sense for bursty use-cases, this is a poor fit for compute-heavy workloads: you’d be paying 85% of the cost for 40% (or less) of the performance of a non-burstable instance.
Poor Performance of Burstable Instances#
The benchmarks ran faster on m6i.large instances than on t3.large. At a high-level, we can see this by comparing the total number of instance-hours:

Let’s dig into why the non-burstable instances are faster than the burstable instances.
Modern Chipset#
Part of the explanation is that m6i offers faster and newer Intel CPUs, as well as faster networking:
Burstable (t3.large) |
Non-burstable (m6i.large) |
|
|---|---|---|
Processor |
Up to 3.1 GHz Intel Xeon Scalable processor (Skylake 8175M or Cascade Lake 8259CL) |
Up to 3.5 GHz 3rd Generation Intel Xeon Scalable processors (Ice Lake 8375C) |
Network Performance |
Up to 5 Gbps |
Up to 10 Gbps |
But that’s not the full story. To get a deeper understanding, let’s take a closer look at a few different workloads.
Workload 1: Network and disk with array workload#
The following workload stresses network and disk. We construct a large random array (too large for memory) and then rechunk it twice across the network, forcing a full shuffle of all of the data:
x = da.random.random((50,000, 50,000))
x.rechunk((50,000, 20)).rechunk((20, 50,000)).sum().compute()
Coiled collects extensive metrics on workloads. We publicly host the metrics for the benchmark suite on a public Grafana server to aid community development. We can go and look at them there.
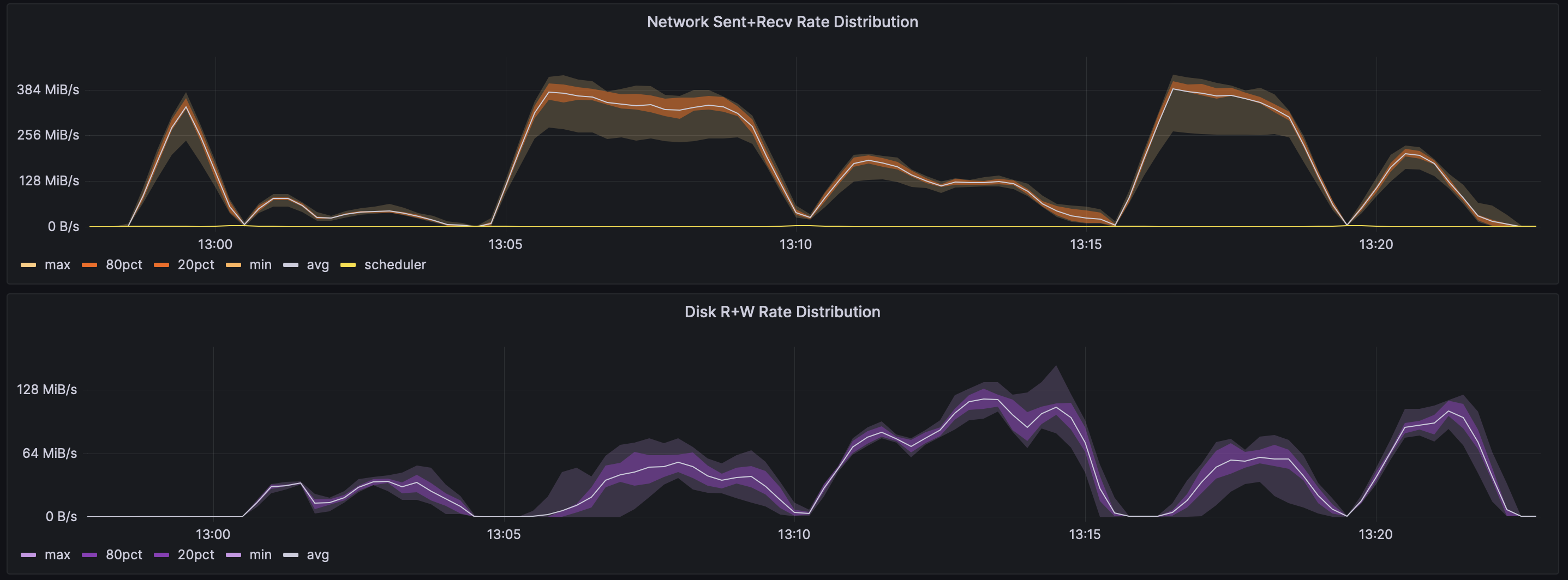
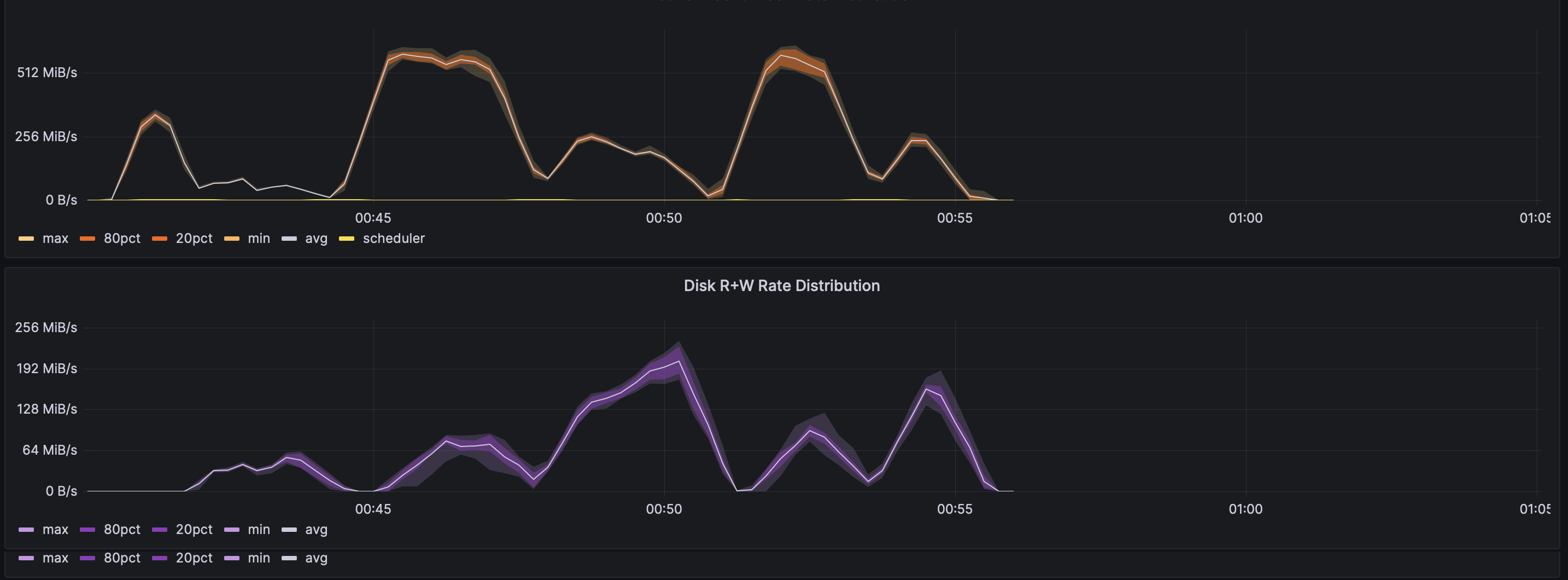
Let’s take a look at the network and disk metrics for the same tests on m6i.large and t3.large instances, moving 1.5TB over 25 minutes or 15 minutes respectively:
t3.large#
m6i.large#
The m6i.large instances ran the same workload in only 15 minutes, compared to 25 minutes on t3.large instances. This is explained by two facts:
First, peak speeds are higher on m6i.large instances:

Second, variance was higher across burstable instances. This is evident from the bands of color on the Grafana charts, which are narrower for the m6i.large run, but thicker for the t3.large run.
The m6i.large instances get faster network and disk speeds, and they get these speeds more consistently.
You can see these charts (and lots of others!) for yourself on our Grafana server:
Workload 2: XGBoost + Optuna with moderate CPU use#
When we started to compare performance on burstable and non-burstable instances, one of the more surprising discoveries was that burstable instances showed much more “steal” CPU time. This came up in the XGBoost + Optuna benchmark:
def train_model(**study_params):
model = xgboost.dask.train(
None,
{"tree_method": "hist", **study_params},
d_train,
num_boost_round=4,
evals=[(d_train, "train")],
)
predictions = xgboost.dask.predict(None, model, x_test)
return mean_squared_error(
y_test.to_dask_array(),
predictions.to_dask_array(),
squared=False,
)
def objective(trial):
params = {
"n_estimators": trial.suggest_int("n_estimators", 75, 125),
"learning_rate": trial.suggest_float("learning_rate", 0.5, 0.7),
"colsample_bytree": trial.suggest_float("colsample_bytree", 0.5, 1),
"colsample_bynode": trial.suggest_float("colsample_bynode", 0.5, 1),
"colsample_bylevel": trial.suggest_float("colsample_bylevel", 0.5, 1),
"reg_lambda": trial.suggest_float("reg_lambda", 0, 1),
"max_depth": trial.suggest_int("max_depth", 1, 6),
"max_leaves": trial.suggest_int("max_leaves", 0, 2),
"max_cat_to_onehot": trial.suggest_int("max_cat_to_onehot", 1, 10),
}
return train_model(**params)
study = optuna.create_study(study_name="nyc-travel-time-model")
study.optimize(objective, n_trials=3)
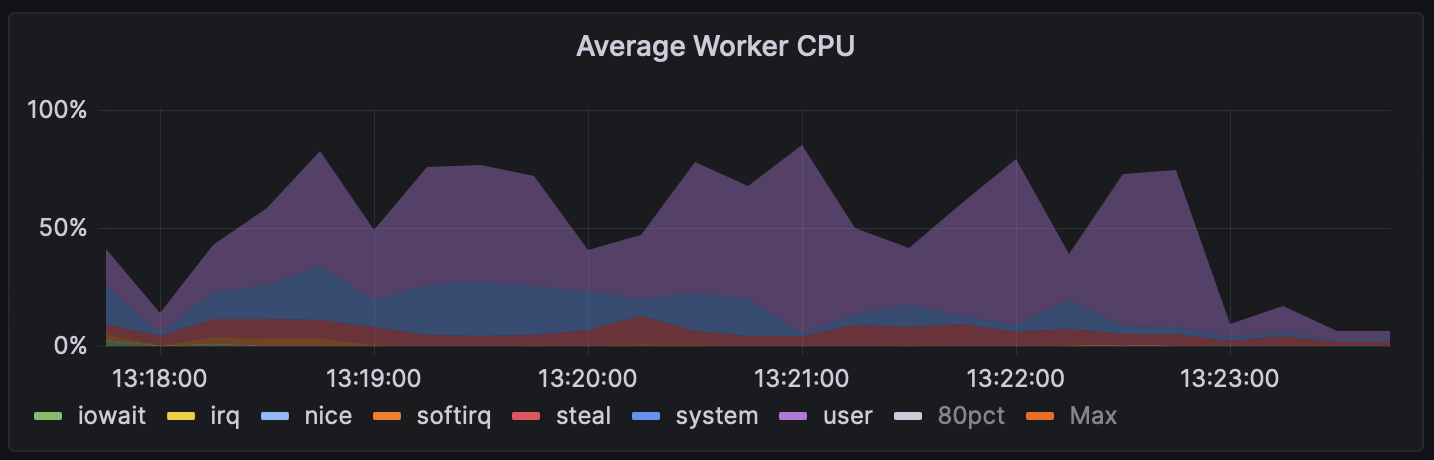
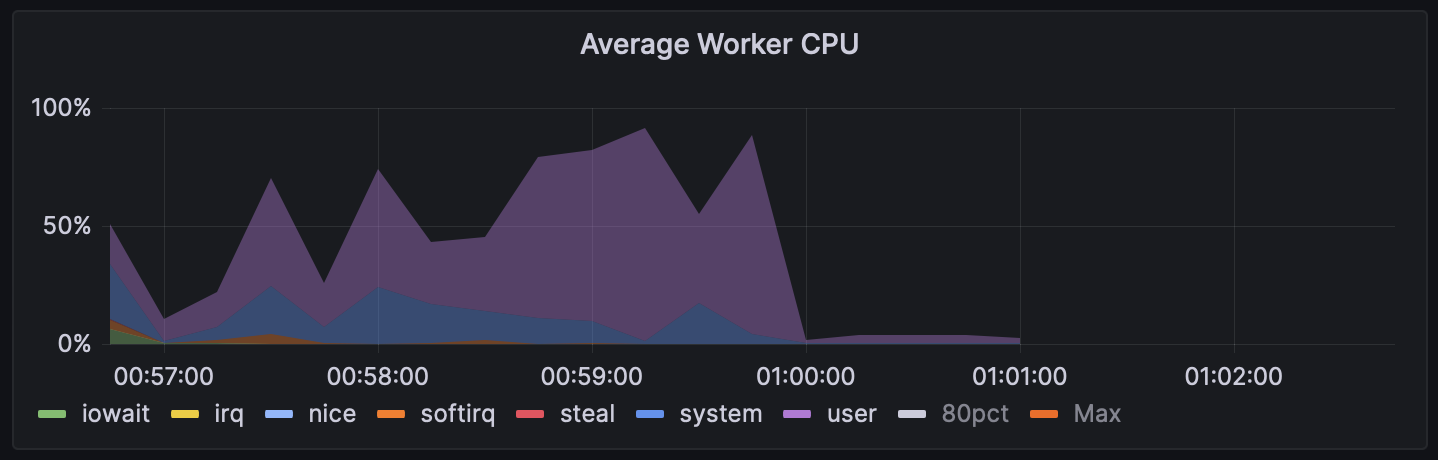
This benchmark uses little network or disk, and while it doesn’t saturate the CPU, it does have a consistent level of moderate CPU utilization. Here is the CPU utilization throughout the benchmark run:
t3.large (full Grafana dashboard)#
m6i.large (full Grafana dashboard)#
The m6i run is faster. Interestingly, there is also more “steal” (shown in red) on the t3 instances, while there’s almost none on the m6i instances. The non-burstable m6i instances have more of CPU use in user and system, where the t3.large instances had on average 5–12% steal.
What is steal CPU use you ask? According to the Linux man page for mpstat,
steal [is] the percentage of time spent in involuntary wait by the virtual CPU or CPUs while the hypervisor was servicing another virtual processor.
With a few exceptions, EC2 instances are run on much larger hosts. The physical server runs a hypervisor that virtualizes the resources and ensures that every EC2 instance gets its fair share of the actual hardware. Steal is the overhead of this sharing—it’s the amount of time your code spends waiting to get access to an actual CPU.
While you sometimes see steal on non-burstable instances, it’s very low. Burstable instances consistently show much higher steal. We haven’t found a detailed explanation from AWS but we suspect this has two possible causes:
Burstable instances are cheaper because AWS can “overbook” the hardware, much like an airline might overbook a flight. As long as enough people are underutilizing the CPU (or enough people are running late for the flight), everyone can get what they want. But sometimes more of the workloads want to utilize more of the CPU (or everyone wants the seat they paid for), and that’s when someone has to get bumped.
On burstable instances, the hypervisor itself also has more work to do, since it tracks CPU credits. While AWS doesn’t say this, it’s possible that tracking burst (and the associated costs) also adds overhead. Or maybe this isn’t the case, since the hypervisor on Nitro instances is actually offloaded to separate, dedicated hardware.
Regardless of the underlying cause, we’ve seen that burstable instances very frequently show 5–10% “steal” (or more), while non-burstable instances almost never have more than 1 or 2% steal.
The upshot is that for workloads with moderate CPU utilization—such as typical data engineering workloads—you’ll often end up paying more for burstable instances and getting worse performance.
Spot availability for burstable instances#
Spot instances are another way to save money in the cloud. Spot instances are cheaper than on-demand instances: often providing 60–70% savings.
However, spot instances have more limited availability than on-demand instances. They’re offered at a discount because they’re unused capacity, and AWS can reclaim your spot instances if there’s more demand for full-priced instances.
It’s possible that even with all the caveats about burstable instances, burstable instances might be best all things considered if you had to choose between
t3 spot instances, and
m6i on-demand instances.
The key question here is whether it’s easier to get t3 spot instances than it is to get m6i spot instances.
Spot capacity varies over time by instance type and by region, so we can’t promise that m6i spot instances aren’t harder to get, but we can share what we see when running our benchmarks at scale.
With the “use best zone” feature (described in our blog post about spot instances), we’ve gotten 100% of the requested m6i.large workers in the last 14 days as spot, thousands of per day:
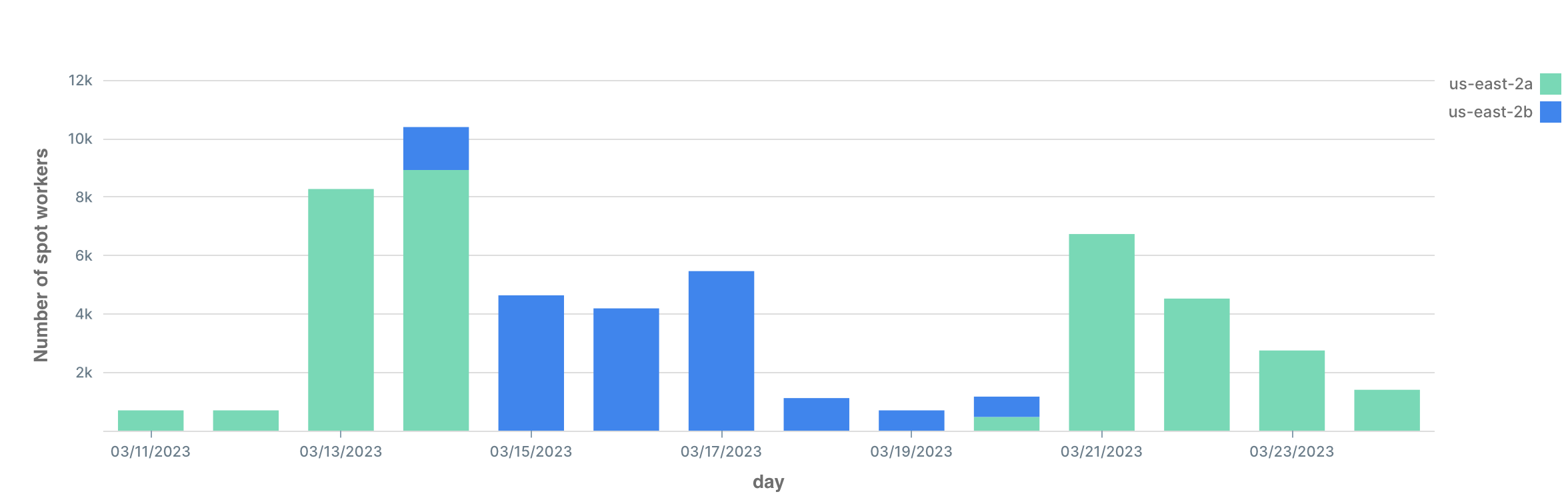
If you care about cost, you should definitely watch your ability to get spot vs on-demand instances (you can see your cost breakdowns as explained in this blog post). But in our experience, we’ve had no trouble getting non-burstable m6i.large spot instances.
Further Reading#
Based on this analysis we’ve set the defaults for Coiled users to non-burstable instance types. We recommend that you do the same. Hopefully the way that we did this analysis helps explain our thinking, and informs how you might make similar decisions in the future.
If you’d like to read more about burstable instances on AWS, here are a few places to start: