Nov 19, 2024
3m read
SLURM-Style Job Arrays on the Cloud with Coiled#
Matthew Rocklin
Update Jan. 9th, 2025: We’ve added documentation for Coiled Batch.
SLURM and other job schedulers have made it easy to run scripts on HPC systems for decades. Job scripts are straightforward and solve a common problem in a way that is familiar to researchers who have had exposure to HPC systems. Heck, I personally used them as a graduate student long before I knew anything about parallel computing.
Unfortunately, the cloud doesn’t offer anything similar with the same level of ease. (It’s oddly difficult to do this on the cloud). We wanted to fix that, and so just released this new feature with Coiled reinventing the SLURM-style job script for the cloud.
Disclaimer: we just pushed this out last week and it’s not polished yet, doesn’t have docs, etc.. It felt easy enough though that we felt safe talking about it early in hope of getting more feedback.
Example: Hello world!#
We’ll give lots more examples below but for now let’s do a trivial Hello world example parallel job script
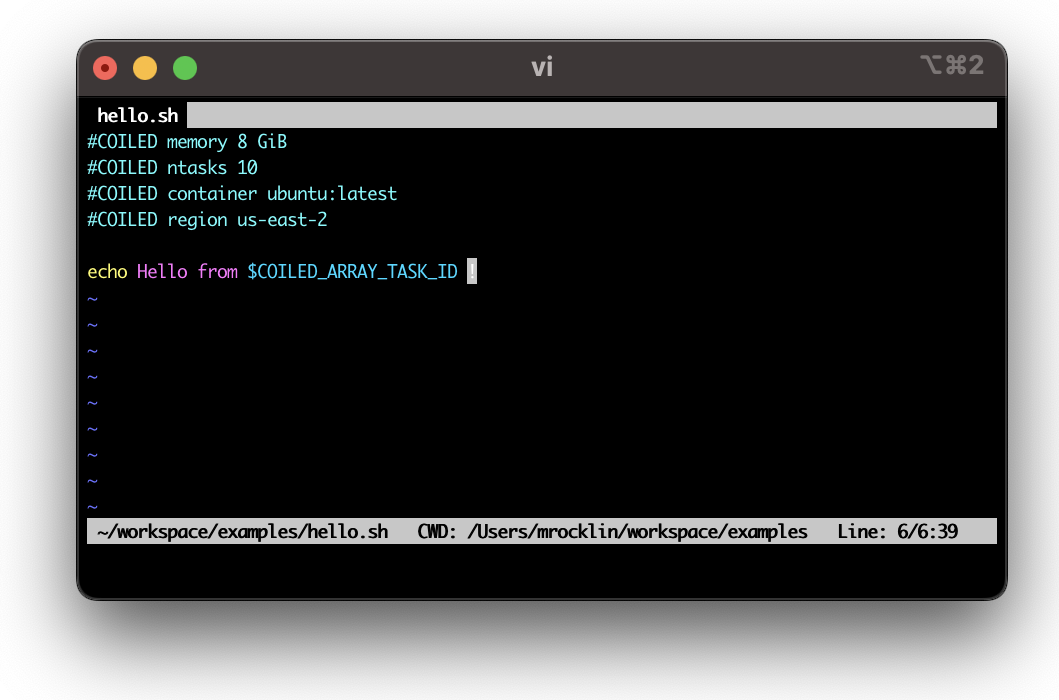
$ coiled batch run hello.sh
Running job array of 10 tasks on 10 VMs...
Cluster Details: https://cloud.coiled.io/clusters/661309?account=dask-engineering
To check status, run:
coiled batch status 661309
$ coiled batch status 661309
Batch Jobs for Cluster 661309 (stopped)
Command: hello.sh
┏━━━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┓
┃ ┃ Assigned ┃ ┃ Start ┃ ┃ ┃ ┃
┃ Array ID ┃ To ┃ State ┃ Time ┃ Stop Time ┃ Duration ┃ Exit Code ┃
┡━━━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━┩
│ 0 │ 10.0.46.1… │ done │ 15:59:46 │ 15:59:46 │ 0s │ 0 │
│ 1 │ 10.0.46.1… │ done │ 15:59:46 │ 15:59:46 │ 0s │ 0 │
│ 2 │ 10.0.46.1… │ done │ 15:59:46 │ 15:59:46 │ 0s │ 0 │
│ 3 │ 10.0.46.1… │ done │ 15:59:46 │ 15:59:47 │ 0s │ 0 │
│ 4 │ 10.0.46.1… │ done │ 15:59:47 │ 15:59:47 │ 0s │ 0 │
│ 5 │ 10.0.46.1… │ done │ 15:59:47 │ 15:59:47 │ 0s │ 0 │
│ 6 │ 10.0.46.1… │ done │ 15:59:47 │ 15:59:47 │ 0s │ 0 │
│ 7 │ 10.0.46.1… │ done │ 15:59:48 │ 15:59:48 │ 0s │ 0 │
│ 8 │ 10.0.37.50 │ done │ 15:59:48 │ 15:59:48 │ 0s │ 0 │
│ 9 │ 10.0.46.1… │ done │ 15:59:48 │ 15:59:48 │ 0s │ 0 │
└──────────┴────────────┴───────┴───────────┴───────────┴──────────┴───────────┘
And we can easily go and get logs from all the machines at once
$ coiled logs 661309 | grep Hello
2024-11-19 15:59:46.131000 Hello from 0 !
2024-11-19 15:59:46.419000 Hello from 1 !
2024-11-19 15:59:46.743000 Hello from 2 !
2024-11-19 15:59:47.019000 Hello from 3 !
2024-11-19 15:59:47.324000 Hello from 4 !
2024-11-19 15:59:47.587000 Hello from 5 !
2024-11-19 15:59:47.862000 Hello from 6 !
2024-11-19 15:59:48.256000 Hello from 7 !
What Does This Do?#
We …
Inspect your script
Spin up appropriate machines as defined by the comments (this takes about 30s)
Download your software onto them (maybe another 30-60s)
(in this case a Docker image, but Coiled’s environment synchronization works here too)
Run your script
Shut down the machines.
Your script can do anything. It doesn’t have to be Dask related, or even Python related (indeed the echo program used above predates the Python language).
This is very simple, but also very powerful. Let’s look at a few more examples:
Cloud Job Script Examples#
Our example from above, for completeness’ sake.
#!/bin/bash
#COILED n-tasks 10
#COILED memory 8 GiB
#COILED container ubuntu:latest
#COILED region us-east-2
echo Hello from $COILED_BATCH_TASK_ID
We can submit python scripts too
#COILED n-tasks 10
#COILED memory 8 GiB
#COILED region us-east-2
import os
print("Hello from", os.environ["COILED_BATCH_TASK_ID"])
Here we also drop the container directive, and rely on Coiled’s environment synchronization to copy all of our Python libraries to the remote machines automatically.
A common pattern is to list many files, get the ith file, and run some command on that file.
#COILED n-tasks 1000
#COILED memory 8 GiB
#COILED region us-east-2
import os
import s3fs
s3 = s3fs.S3FileSystem()
# Get the i'th file to process
task_id = int(os.environ["COILED_BATCH_TASK_ID"])
filenames = s3.ls("my-bucket")
filename = filenames[task_id]
# Process that file
def process(filename):
result = ...
return result
result = process(filename)
# Store result
s3.put(...) # put result back in S3 somewhere
We can ask for any hardware on any cloud, including a collection of GPUs machines
#COILED n-tasks 100
#COILED vm-type g5.xlarge
#COILED region us-east-2
import torch
model = ...
for epoch in range(50):
model.train()
...
When you use a GPU machine with Coiled’s environment sync feature, it will automatically install GPU equivalents to local packages like pytorch, along with all the necessary NVIDIA CUDA drivers. So you can develop locally on your CPU or Apple hardware:
$ python train.py # Uses your local CPU
And when you’re ready to run at full scale you can launch your script to run on many GPU machines:
$ coiled batch run train.py # Uses many cloud GPUs
Status and Logs#
Just like on HPC, it’s easy to get the status of all jobs in your Coiled workspace. This also includes the approximate cloud cost for each job (we’ve seen people be curious about this in the past).
$ coiled batch status
┏━━━━━━━━━━━━┳━━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━┓
┃ Cluster ID ┃ State ┃ Tasks Done ┃ Submitted ┃ Finished ┃ Approx Cloud Cost ┃ User Command ┃
┡━━━━━━━━━━━━╇━━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━┩
│ 661309 │ done │ 10 / 10 │ 15:58:50 │ 15:59:48 │ $0.01 │ hello.sh │
│ 659567 │ done │ 10 / 10 │ 2024-11-18 17:25:08 │ 2024-11-18 17:26:07 │ $0.01 │ hello.sh │
│ 658315 │ done │ 10 / 10 │ 2024-11-17 16:24:27 │ 2024-11-17 16:25:20 │ $0.01 │ hello.sh │
│ 658292 │ done │ 20 / 20 │ 2024-11-17 15:28:44 │ 2024-11-17 15:29:39 │ $0.02 │ hello.sh │
│ 658288 │ done │ 0 / 20 │ 2024-11-17 15:24:32 │ │ $0.02 │ hello.sh │
│ 657615 │ done │ 0 / 10 │ 2024-11-16 20:32:46 │ │ $0.01 │ hello.sh │
│ 656571 │ done │ 10 / 10 │ 2024-11-15 14:32:35 │ 2024-11-15 14:33:35 │ $0.01 │ hello.sh │
│ 655848 │ done │ 20 / 20 │ 2024-11-14 23:56:06 │ 2024-11-14 23:58:01 │ $0.01 │ echo 'Hello, world' │
└────────────┴─────────┴────────────┴─────────────────────┴─────────────────────┴───────────────────┴─────────────────────┘
Shoutout to Python’s rich library for the nice formatting 🙂
And while you can always look at jobs on the Cloud UI, we also provide a convenient way to get logs given a cluster ID (this is true of all Coiled jobs)
$ coiled logs 661309 | grep Hello
2024-11-19 15:59:46.131000 Hello from 0 !
2024-11-19 15:59:46.419000 Hello from 1 !
2024-11-19 15:59:46.743000 Hello from 2 !
2024-11-19 15:59:47.019000 Hello from 3 !
2024-11-19 15:59:47.324000 Hello from 4 !
2024-11-19 15:59:47.587000 Hello from 5 !
2024-11-19 15:59:47.862000 Hello from 6 !
2024-11-19 15:59:48.256000 Hello from 7 !
2024-11-19 15:59:48.315000 Hello from 8 !
2024-11-19 15:59:48.508000 Hello from 9 !
Making Common Things Easy#
This kind of embarrassingly parallel workload is super common.
We saw Python users struggling with the services provided by cloud providers like AWS Batch, GCP Cloud Run, or Azure Batch and thought that this little utility on top of Coiled might make it easier for these users get use out of the cloud.
We hope you like it! As always, if you want to try out Coiled, you can get started at coiled.io/start.