Jun 11, 2025
4 min read
Coiled: A GPU-accelerated serverless alternative to AWS Lambda#
AWS Lambda is widely used for event-driven workloads that require quick, lightweight execution without infrastructure management. But when it comes to tasks that demand GPU acceleration, like training deep learning models, running inference on images, or performing parallel scientific simulations, Lambda falls short.
With no GPU support, a 15-minute execution limit, and container image size limits, AWS Lambda isn’t designed for compute-heavy or memory-intensive applications.
In this post, we’ll explore how Coiled provides a serverless Python experience with full GPU support, offering a flexible, Lambda-like alternative for GPU-accelerated computing in your own AWS account.
Why Lambda alone falls short#
AWS Lambda was specifically designed for short-lived compute tasks. And for these for small, event-driven tasks it works really well. This includes things like:
Responding to API Gateway requests
Parsing log files
Short-running Python scripts
But it falls short for high-performance compute due to a number of limitations.
Feature |
AWS Lambda |
Coiled |
|---|---|---|
GPU support |
❌ No |
✅ Yes |
Spot instances |
❌ No |
✅ Yes |
Max execution time |
15 minutes |
No limit, configurable |
Container image size |
Capped at 10 GB, uncompressed |
No limit, package sync or Docker |
Scale-to-zero |
✅ Yes (by default) |
✅ Yes (by default) |
Memory |
Capped at 10 GB |
No limit, configurable |
vCPU |
Proportional to memory, not directly configurable |
No limit, configurable |
AWS Lambda imposes several architectural constraints that limit its suitability for GPU-based or high-performance workloads. Memory and vCPU are tied together, maxing out at 10 GB and proportional CPU allocation, with no GPU support. Container images must remain under 10 GB uncompressed, which is often too small for GPU-accelerated Python workloads that bundle frameworks like PyTorch, TensorFlow, CUDA, and cuDNN (not to mention any pre-trained model weights or scientific dependencies). By contrast, Coiled offers additional flexibility: define your software environment using conda or pip, use Docker images of any size, and deploy clusters with GPU-backed instances on demand, all without container size limits or infrastructure overhead.
Coiled: A serverless GPU alternative#
With Coiled, you can run Python workloads on-demand in your AWS account with optional GPU support. Coiled spins up EC2 instances as you need them, replicating your local Python environment on remote VMs. With Coiled, you can:
Spin up GPU-backed clusters (e.g.,
g5.xlarge)Run Torch, TensorFlow, or custom CUDA workloads
Use Spot instances for cost efficiency
Use cases for GPUs + Coiled#
Deep learning inference at scale
Image/video processing pipelines
Scientific simulations (e.g., genomics)
ETL pipelines with GPU libraries
Parallel compute tasks in finance or physics
Step-by-step guide: Running GPU-accelerated workloads on Coiled#
Sign up#
First, sign up for Coiled using GitHub, Google, or by making your own username and password.
Install Coiled#
Next, we’ll install Coiled. We’ll also include PyTorch, since this example will go through training a PyTorch model on a GPU.
$ pip install torch torchvision coiled
$ conda create -n env python=3.11 pytorch torchvision coiled
$ conda activate env
Train PyTorch model#
Next, we’ll define our PyTorch model:
import torch.nn as nn
import torch.nn.functional as F
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(3, 1024, 5)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(1024, 16, 5)
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = x.view(-1, 16 * 5 * 5)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
Now that we have our model, let’s train it on our dataset on the hardware of our choosing. Fortunately, PyTorch makes it straightforward to utilize different types of hardware that are available locally.
Below is a train function that takes a PyTorch device as input (defaults to "cpu"), loads the CIFAR10 dataset, trains our model on the dataset on the specified hardware, and returns the trained model.
import torch
import torchvision
import torch.optim as optim
import torchvision.transforms as transforms
def train(device="cpu"):
# Select hardware to run on
device = torch.device(device)
model = Net()
model = model.to(device)
# Load CIFAR10 dataset
trainset = torchvision.datasets.CIFAR10(
root='./data', train=True, download=True, transform=transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2470, 0.2435, 0.2616))]),
)
trainloader = torch.utils.data.DataLoader(
trainset, batch_size=256, shuffle=True,
)
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.001, momentum=0.9)
for epoch in range(10):
print(f"Epoch {epoch + 1}")
model.train()
for batch in trainloader:
# Move training data to device
inputs, labels = batch[0].to(device), batch[1].to(device)
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
return model.to("cpu")
Run on a cloud GPU#
Our train function can now be run on any hardware that’s available locally. To train our model on a GPU, we’ll use Coiled Functions to lightly annotate our existing train function to run on a GPU-enabled cloud VM.
import coiled
@coiled.function(
vm_type="g5.xlarge", # NVIDIA A10 GPU instance
region="us-west-2",
)
def train(device="cpu"):
# Same training code as before
...
Now when the train function is run, Coiled will automatically handle provisioning a cloud VM (a g5.xlarge instance on AWS in this case), installing the same software that’s installed locally on the cloud VM, running our train function on the VM, and returning the result back locally.
model = train(device="cuda") # Train model on cloud GPU
This takes ~4.5 minutes to run (including VM spinup time) and costs ~$0.08 (running locally would have taken ~1.5 hours).
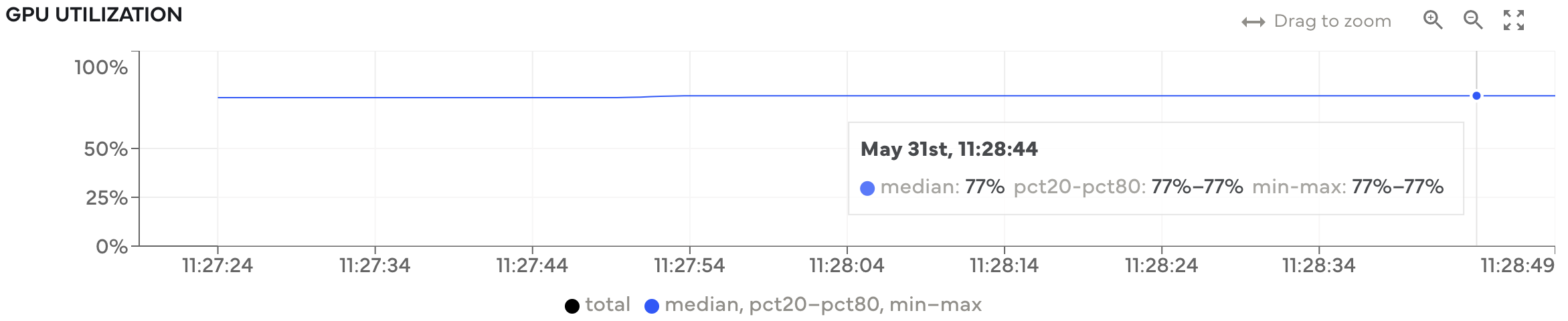
GPU utilization throughout model training. Utilization is typically high throughout, meaning we’re utilizing the available hardware well.#
How does Coiled compare to other serverless tools?#
Tools like AWS Lambda, Google Cloud Functions, and Azure Functions are optimized for lightweight, fast-response tasks (such as web endpoints or trigger-based coordination), but they are less suited for heavy data processing or GPU-accelerated workloads. We also find these cloud provider-specific tools leave a lot to be desired in terms of developer experience and often require cloud provider-specific knowledge. See the full comparison for more details.
Tools like Modal and Coiled on the other hand, prioritize ease of use, making it easy for anyone to use GPUs on the cloud. Modal, for example, offers cold start times around one second and is an excellent choice for latency-sensitive applications. However, this comes with tradeoffs, like higher cost per compute unit (often 4–5x raw EC2 cost) and less flexibility in hardware and environment setup. Coiled functions, on the other hand, are cheaper at scale (raw EC2 instances are spun up as needed) and offer more security and flexibility (everything runs in your cloud account). For a deeper dive, read the full comparison on Coiled vs. Modal.
In short:
If you need sub-second response times for short-lived web requests, tools like Modal are a good fit.
If you’re doing large-scale, resource-intensive workloads, and have more specific security requirements, Coiled is a better fit.
Next steps#
Serverless functions aren’t the only way to run GPU-accelerated workloads with Coiled. You can also use:
Batch jobs: Like AWS Batch, but a lot easier to use.
Jupyter notebooks: Run a Jupyter Notebook on AWS/GCP/Azure.
Distributed compute: Speed up and scale your Python workflows with Dask clusters.