Apr 19, 2024
6m read
Dask vs. Spark#
People often ask “How does Dask compare to Spark?”
Apache Spark has been the industry standard for big data, although it’s not clear that anyone especially loves it, especially in the Python space. The promise of Spark is that it won’t topple over no matter how large your data gets, and for years it’s been the best big data tool available.
Today, though, there are a number of modern solutions for churning through TBs of data. Dask, in particular, is an attractive alternative to Spark because it’s:
Performant at large scale (and faster than Spark)
Easy to use (and easier to debug)
Highly flexible (does everything from ETL to machine learning)
We’re Dask fans and this post isn’t shy about showing that bias. For a less biased treatment of this same topic, see the OSS Dask documentation page where we’ve tried to keep a more balanced tone.
Dask is Faster than Spark#
We compared Dask and Spark on the TPC-H benchmark suite and can confidently claim that Dask is not only easier to use, but often faster and more reliable than Spark. See DataFrames at Scale Comparison: TPC-H which compares Dask, Spark, Polars, and DuckDB performance to learn more.
We’ll show results from running the TPC-H benchmarks locally on a 10 GB dataset and on the cloud on a 10 TB dataset. These two cases are important because developers typically want to iterate locally on a small sample before scaling out to the full dataset on a production job on the cloud.
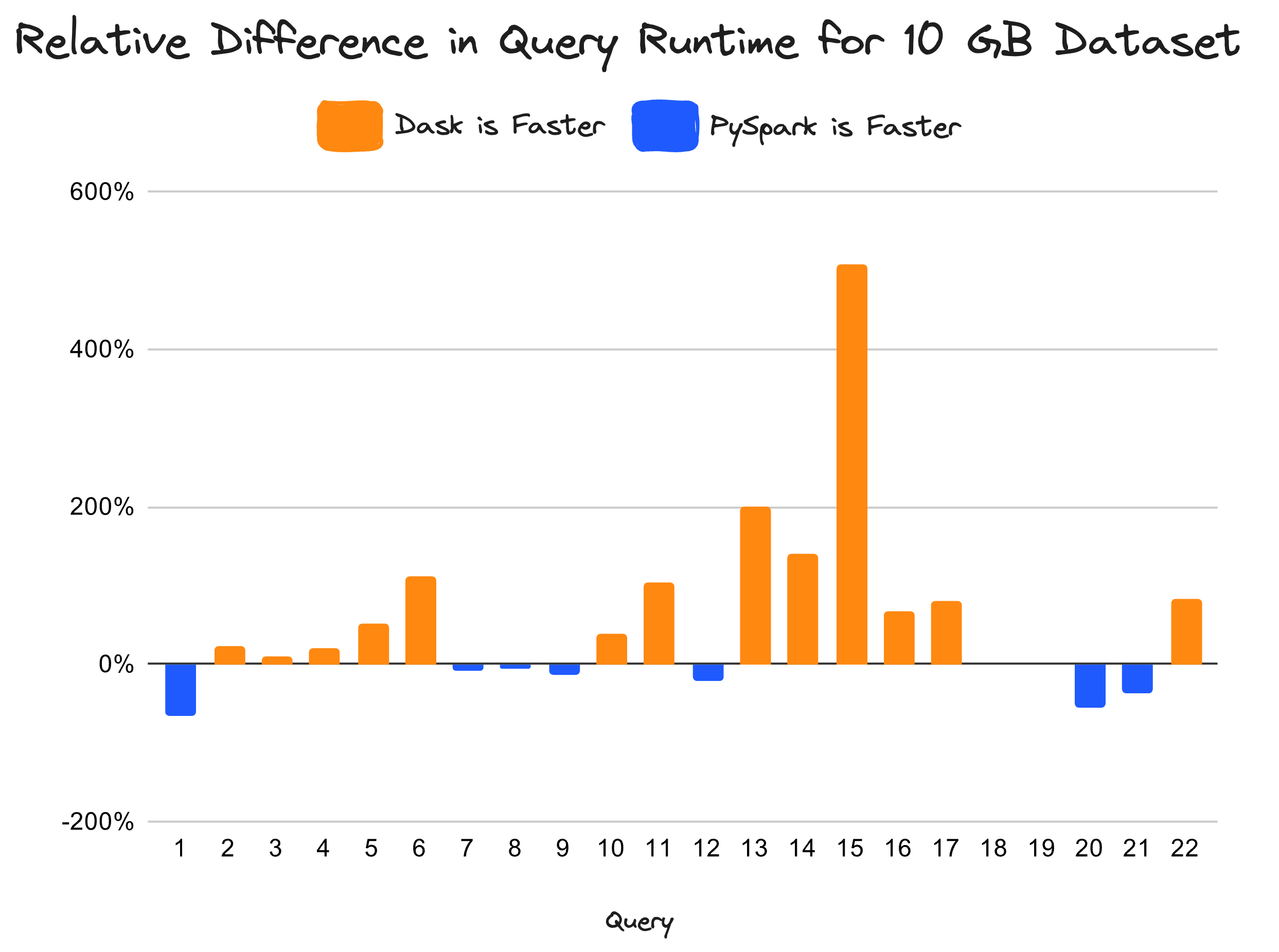
Dask consistently outperforms PySpark on a 10 GB dataset that fits on a typical laptop. Dask is up to 507% faster than Spark.#
When running the TPC-H benchmarks locally on an M1 MacBook Pro, Dask is up to 507% faster than Spark. Since Dask is faster locally, this makes it easier for developers to iterate quickly.
There were some challenges with all queries successfully completing when scaling the benchmarks to a 10 TB dataset. Originally, we ran these queries on an underprovisioned cluster (32 x m6i.xlarge / 128 CPUs / 512 GB). Dask failed on three of the 22 queries, but handled everything else gracefully (albeit slowly). Spark, however, failed on all queries, either due to running out of memory, running out of disk, or running into an hour-long timeout.
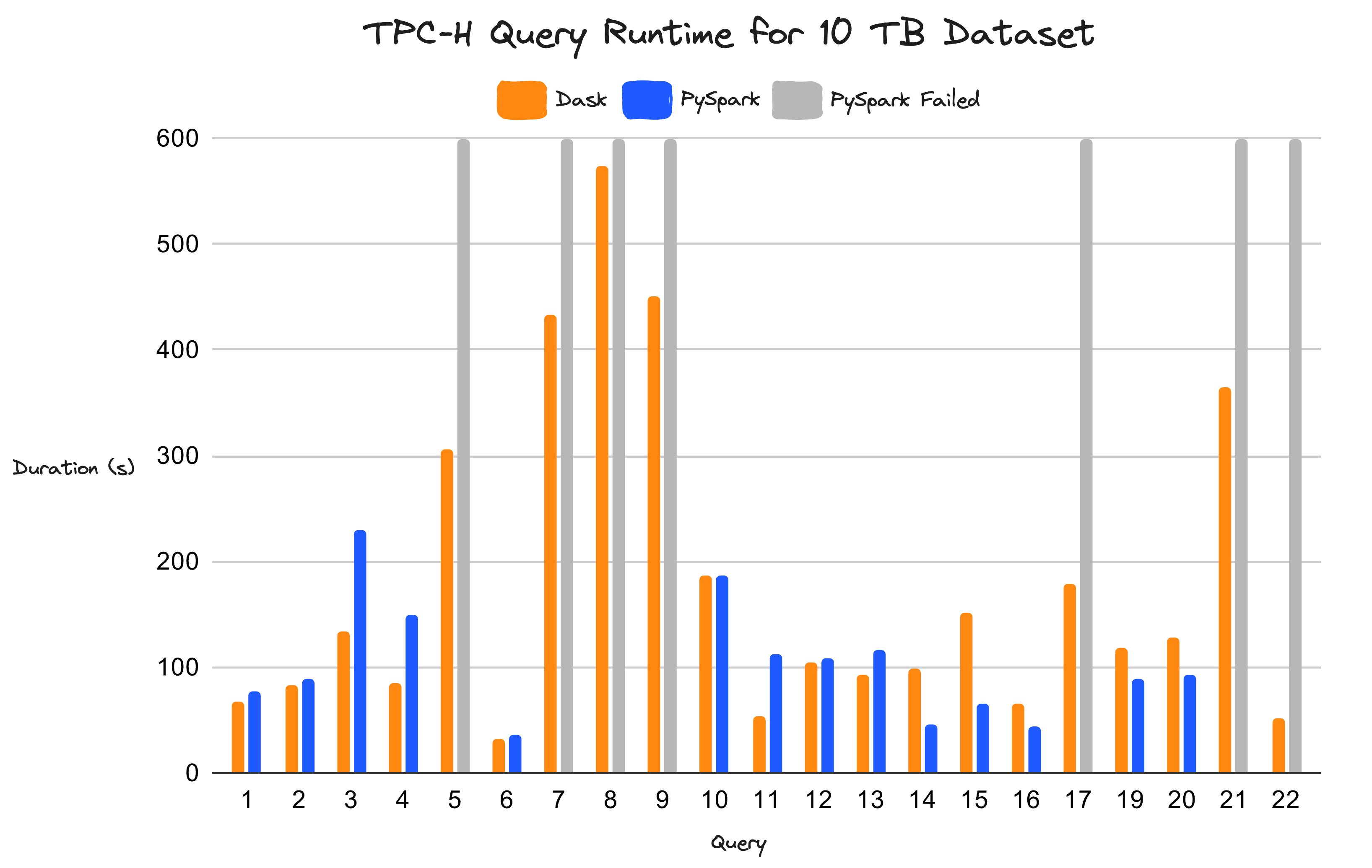
Dask can finish many queries that PySpark cannot on a cluster with 5 TB of memory. PySpark was unable complete seven of the 22 queries (shown in grey).#
We also ran the benchmarks on a cluster with 5 TB of memory and 1280 CPU cores. This should be sufficient, since systems should be able to deal with data that is modestly larger than RAM. While Dask completed 21 of 22 queries, Spark either failed or ran into an hour-long timeout on seven queries. This is problematic because it causes engineers to over-provision clusters with too large machines by habit, ultimately increasing cost.
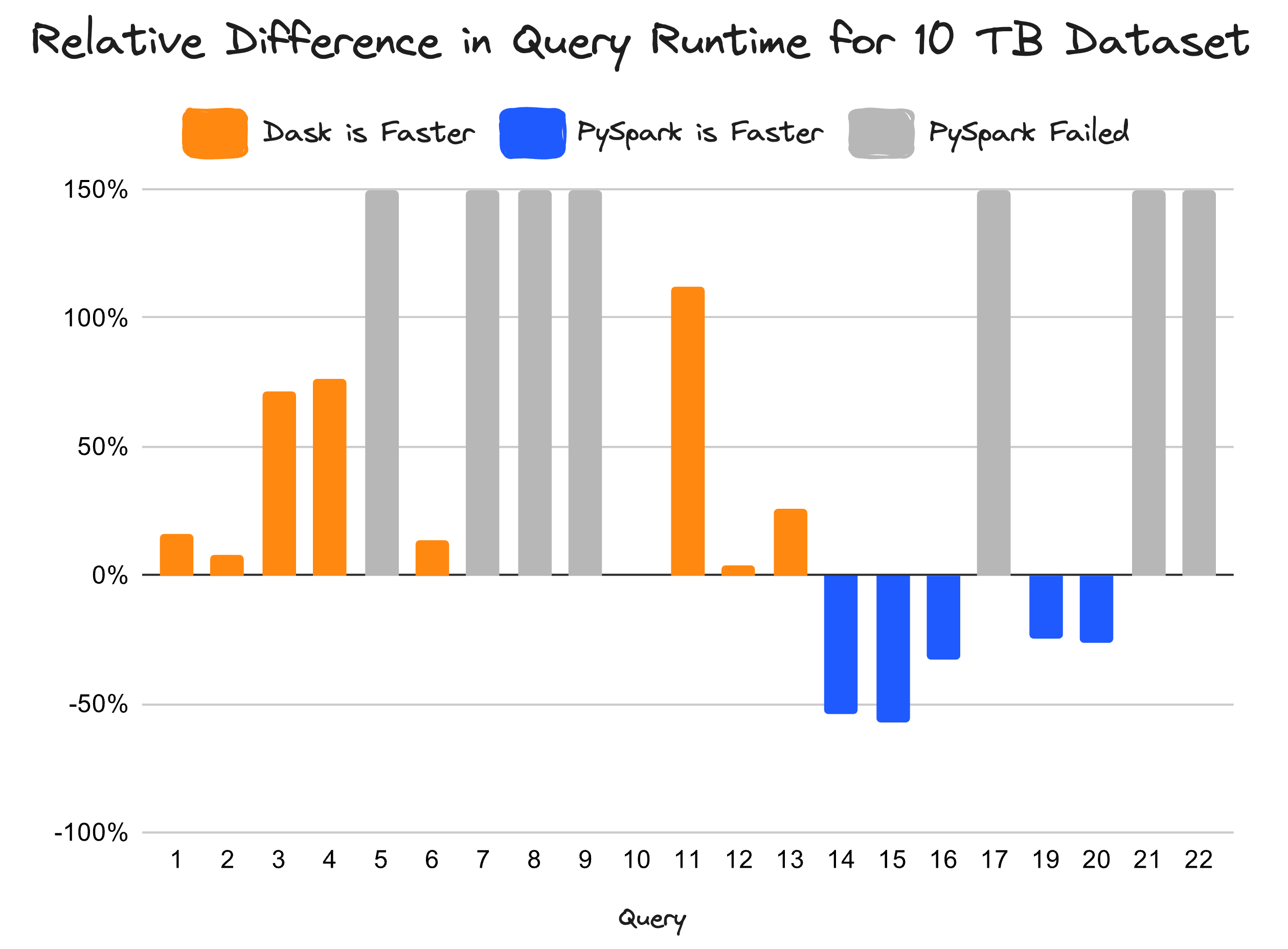
Relative difference between Dask vs PySpark. Dask is up to 112% faster than Spark for queries they both completed.#
For queries that Dask and PySpark completed, Dask is often faster. This is largely due to a number of engineering improvements in Dask, see Dask DataFrame is Fast Now to learn more.
Dask is easier to use than Spark#
People are both slower and more expensive than computers, so we optimize for people. Users frequently praise how much easier Dask is to use than Spark.
A lot of the Spark internals are run on the JVM, so it’s actually not that easy to debug. You spend a lot of time on Stack Overflow trying to figure out what did I do wrong, why am I getting this traceback. It was painful and we wanted to use something that was not as difficult to actually debug.
- Sébastien Arnaud, CDO/CTO at Steppingblocks, on why they switched from Spark to Dask
Easy to learn#
Dask is well-integrated in the larger Python ecosystem; it complements and enhances other popular libraries like pandas, NumPy, and scikit-learn. Many users are already familiar with Python for handling large datasets. Dask looks and feels a lot like pandas, so it’s easier to get started quickly.
import pandas as pd
import dask.dataframe as dd
# use pandas when your data fit in memory
df = pd.read_parquet("small-data.parquet")
# use Dask when you can't read in your data on a single machine
df = dd.read_parquet("large-data.parquet")
Easy to set up#
Historically, Spark had better support for enterprise data sources like Delta Lake and Snowflake. Dask has caught up though, and today with projects like delta-rs (the Rust re-implementation of Delta Lake) and Snowflake’s bulk read/write capabilities, Dask gives a first-class user experience on-par with any other technology.
You can create a Delta Lake table from a pandas dataframe and use dask_deltatable to read in a Delta Lake table into Dask DataFrame.
import deltalake
import pandas as pd
df = pd.read_csv("...")
deltalake.write_table("mytable", df, mode="append")
import dask_deltatable
df = dask_deltatable.read_deltalake("mytable", datetime="2020-01-01")
With dask_snowflake, you can read from a Snowflake table into a Dask DataFrame.
import dask_snowflake
example_query = """
SELECT *
FROM SNOWFLAKE_SAMPLE_DATA.TPCH_SF1.CUSTOMER;
"""
df = read_snowflake(
query=example_query,
connection_kwargs={
"user": "...",
"password": "...",
"account": "...",
},
)
Easy to Debug#
Debugging Spark is painful, often accounting for most of the time spent with the technology. In contrast, Dask works hard to make this experience almost as easy as it is in a single-machine context. Dask users especially love the Dask dashboard, which gives them a lot of understanding about how their computation is going.
Easy to Deploy#
Deploying Spark, or even configuring it locally, is a pain. Spark users often mention it requires digging through docs and finding obscure configuration settings just to get anything running. We really don’t see it in the wild, except under some SaaS deployment solution like Databricks, EMR, Synapse, Dataproc, etc.
Dask on the other hand has SaaS solutions like Coiled, but is also often deployed “raw” using systems like Kubernetes or HPC job managers (see the Dask Deployment docs). We’re a bit biased, but the main SaaS solution, Coiled, is way easier to use than any of the Spark SaaS solutions.
Dask does more than Spark#
The first questions you ask yourself are:
“Can this tool actually solve my problem?”
“How painful will it be?”
For Spark, if your problem is SQL queries, DataFrames, or streaming analytics then the answer is “yes, this tool definitely solves my problem”. For Dask these all apply as well, and also more applications like:
Training ML models with XGBoost or PyTorch
HyperParameter optimization with Optuna
Workflow management with tools like Prefect or Dagster
Highly custom parallelism and ad-hoc workflows
Wrangling large multi-dimensional data, such as in imaging or processing simulation output
Internally, Spark is fundamentally a MapReduce engine. It applies the same function across many inputs uniformly, shuffles those results around, and reduces the results. This pattern is both simple and powerful, and lets Spark build up abstractions like DataFrames and SQL.
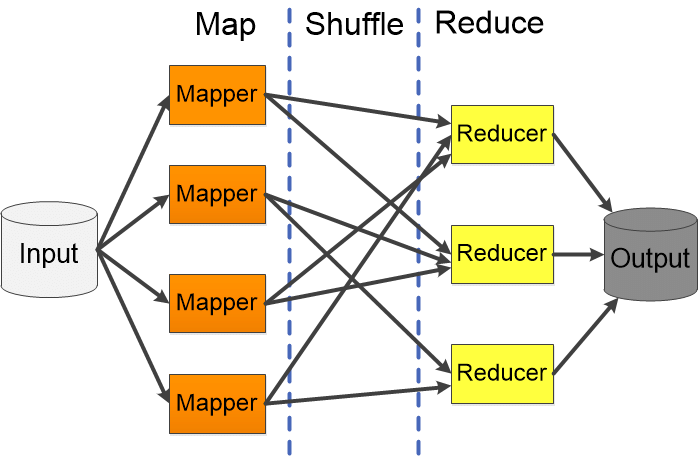
Map-Shuffle-Reduce: Apache Spark always operates on lots of data in bulk using the same operations.#
However, many applications (like those listed above) can’t be written down as a MapReduce style problem. These problems can not be efficiently solved with Spark, at least not without a lot of pain, and so people either build their own solution, or they build on tools like Dask.
Instead of using MapReduce, Dask follows a task scheduling approach. This provides more flexibility, which has made Dask a powerful backend for a modern generation of tools, ranging from ML training systems like XGBoost, to workflow managers like Prefect and Dagster, all of which can back themselves with Dask clusters for scalable computing. Additionally, disciplines with a high degree of complexity, like finance and geoscience, prefer Dask because they can build arbitrarily complex computations on a fine-grained task-by-task basis.

Task graph of a credit model. Dask uses dynamic task scheduling, which can handle weirder situations (which come up a lot in Python workloads).#
Conclusion#
In general, both Spark and Dask can probably do what you want (unless you’re doing something very strange). Speaking with our Dask bias, we’re pretty proud of the decisions and tradeoffs Dask has made and are excited to see Dask continue to make impressive performance gains.
It’s also pretty easy to try out for yourself, either locally or on the cloud:
Dask can set itself up easily in your Python session with a LocalCluster.
from dask.distributed import LocalCluster
cluster = LocalCluster()
client = cluster.get_client()
It’s easy to sign up for Coiled to run Dask on the cloud.
from coiled import Cluster
cluster = Cluster(n_workers=100)
client = cluster.get_client()
Once you have a Dask cluster, you can run Python code on that cluster. Here are some examples: