GPUs#
GPUs can provide massive performance boosts for workflows like training ML models, computer vision, analytics, and more. Coiled makes it straightforward to use GPU hardware on the cloud.
@coiled.function(
vm_type="g5.8xlarge", # Specify any GPU instance type
region="us-west-2", # Run in any region
)
def predict(filename):
...
$ coiled run python train.py \ # Run your local scripts
--vm-type g5.8xlarge \ # Specify any GPU instance type
--region us-west-2 # Run in any region
cluster = coiled.Cluster(
n_workers=50,
worker_vm_types="g5.8xlarge", # Specify any GPU instance type
region="us-west-2", # Run in any region
)
$ coiled notebook start \
--vm-type g5.8xlarge \ # Specify any GPU instance type
--region us-west-2 \ # Run in any region
--sync # Sync your local files
This page summarizes how to use GPU hardware effectively with Coiled. In particular, we discuss:
Software#
By default, Coiled’s automatic package synchronization handles inspecting your local Python software environment and replicating it on remote cloud VMs. This works well across both CPU and GPU environments.
In the case where a local software environment doesn’t have a GPU, but remote cloud VMs do, package sync will automatically translate between CPU and GPU versions of commonly used GPU-accelerated packages (for example, PyTorch). This enables you to drive computations on cloud GPUs from any local hardware.
So for example if you want to run PyTorch GPU code on a remote VM, just install PyTorch locally
$ pip install torch
And then run your script on a GPU-enabled VM on Coiled
$ coiled run --gpu python myscript.py
And Coiled will install the appropriate drivers and libraries to match your hardware.
If for some reason automatic package synchronization doesn’t fit your use case well, use a Docker image or manual software environment for managing software.
Hardware#
You can run on any GPU hardware available on your cloud provider, in any region. See the pricing section for a complete list of available instance types.
import coiled
@coiled.function(
vm_type="g5.xlarge", # NVIDIA A10 GPU instance
region="us-west-2",
)
def process(filename):
...
import coiled
@coiled.function(
vm_type="g2-standard-4", # NVIDIA L4 GPU instance
region="us-east1",
)
def process(filename):
...
import coiled
@coiled.function(
vm_type="Standard_NV12ads_A10_v5", # NVIDIA A10 GPU instance
region="westus2",
)
def process(filename):
...
Observability#
GPUs can be costly, so making the most of the available hardware is key. Among other things, Coiled automatically tracks GPU utilization and memory usage metrics to give visibility into how effectively hardware is being used. Often you can tune certain aspects of your workload to achieve higher GPU utilization (for example, ML model batch size).
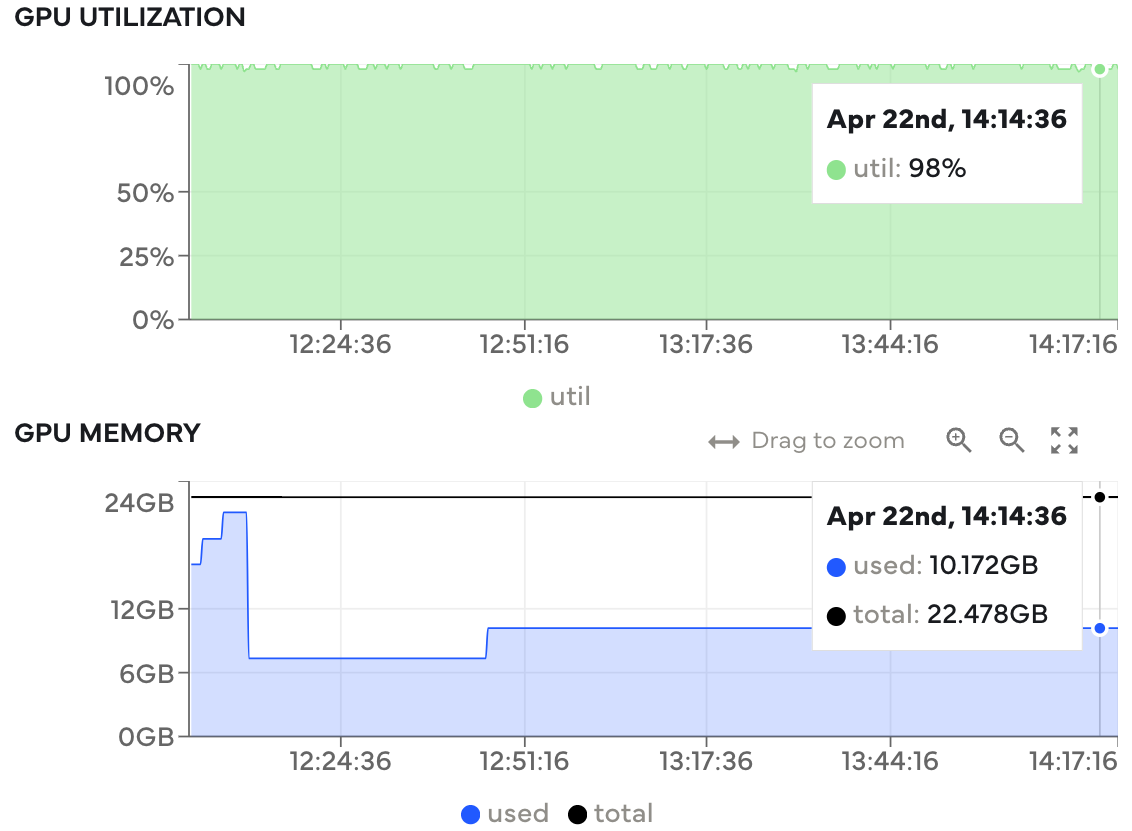
GPU utilization and memory metrics. Utilization is typically high throughout, meaning this workload is utilizing the available hardware well.#
Cost#
It’s always good to know how much your computations will cost and try to avoid unexpected large bills. This is especially true when using GPU hardware, which tends to be more expensive than traditional CPUs.
This section covers GPU hardware costs (see pricing table), setting limits on how much you can spend, and how to avoid idle resources.
Pricing#
Coiled pricing corresponds directly to the size and duration of cloud resources used (see our pricing page). Below is a list of all supported GPU-enabled instances along with their Coiled cost.
Instance type |
CPU |
Memory |
GPU |
Price* |
|---|---|---|---|---|
g4dn.xlarge |
4 |
16 GiB |
T4 |
$0.45/hr |
g6.xlarge |
4 |
16 GiB |
L4 |
$0.45/hr |
g5.xlarge |
4 |
16 GiB |
A10G |
$0.45/hr |
g4dn.2xlarge |
8 |
32 GiB |
T4 |
$0.65/hr |
g6.2xlarge |
8 |
32 GiB |
L4 |
$0.65/hr |
g5.2xlarge |
8 |
32 GiB |
A10G |
$0.65/hr |
g6e.xlarge |
4 |
32 GiB |
L40S |
$0.70/hr |
g6e.2xlarge |
8 |
64 GiB |
L40S |
$0.90/hr |
g4dn.4xlarge |
16 |
64 GiB |
T4 |
$1.05/hr |
g6.4xlarge |
16 |
64 GiB |
L4 |
$1.05/hr |
g5.4xlarge |
16 |
64 GiB |
A10G |
$1.05/hr |
gr6.4xlarge |
16 |
128 GiB |
L4 |
$1.05/hr |
g6e.4xlarge |
16 |
128 GiB |
L40S |
$1.30/hr |
g6.8xlarge |
32 |
128 GiB |
L4 |
$1.85/hr |
g4dn.8xlarge |
32 |
128 GiB |
T4 |
$1.85/hr |
g5.8xlarge |
32 |
128 GiB |
A10G |
$1.85/hr |
gr6.8xlarge |
32 |
256 GiB |
L4 |
$1.85/hr |
g6e.8xlarge |
32 |
256 GiB |
L40S |
$2.10/hr |
g4dn.12xlarge |
48 |
192 GiB |
T4 (x4) |
$3.40/hr |
g6.12xlarge |
48 |
192 GiB |
L4 (x4) |
$3.40/hr |
g5.12xlarge |
48 |
192 GiB |
A10G (x4) |
$3.40/hr |
g6.16xlarge |
64 |
256 GiB |
L4 |
$3.45/hr |
g5.16xlarge |
64 |
256 GiB |
A10G |
$3.45/hr |
g4dn.16xlarge |
64 |
256 GiB |
T4 |
$3.45/hr |
g6e.16xlarge |
64 |
512 GiB |
L40S |
$3.70/hr |
g6e.12xlarge |
48 |
384 GiB |
L40S (x4) |
$4.40/hr |
g6.24xlarge |
96 |
384 GiB |
L4 (x4) |
$5.80/hr |
g5.24xlarge |
96 |
384 GiB |
A10G (x4) |
$5.80/hr |
g6e.24xlarge |
96 |
768 GiB |
L40S (x4) |
$6.80/hr |
g4dn.metal |
96 |
384 GiB |
T4 (x8) |
$6.80/hr |
p4d.24xlarge |
96 |
1.12 TiB |
A100 (x8) |
$6.80/hr |
g6.48xlarge |
192 |
768 GiB |
L4 (x8) |
$11.60/hr |
g5.48xlarge |
192 |
768 GiB |
A10G (x8) |
$11.60/hr |
g6e.48xlarge |
192 |
1.5 TiB |
L40S (x8) |
$13.60/hr |
Instance type |
CPU |
Memory |
GPU |
Price* |
|---|---|---|---|---|
g2-standard-4 |
4 |
16 GiB |
nvidia-l4 |
$0.45/hr |
g2-standard-8 |
8 |
32 GiB |
nvidia-l4 |
$0.65/hr |
g2-standard-12 |
12 |
48 GiB |
nvidia-l4 |
$0.85/hr |
a2-ultragpu-1g |
12 |
170 GiB |
nvidia-a100-80gb |
$0.85/hr |
g2-standard-16 |
16 |
64 GiB |
nvidia-l4 |
$1.05/hr |
ct5lp-hightpu-1t |
24 |
48 GiB |
ct5lp |
$1.45/hr |
ct5l-hightpu-1t |
24 |
48 GiB |
ct5l |
$1.45/hr |
a2-highgpu-1g |
12 |
85 GiB |
nvidia-tesla-a100 |
$1.60/hr |
g2-standard-24 |
24 |
96 GiB |
nvidia-l4 (x2) |
$1.70/hr |
a2-ultragpu-2g |
24 |
340 GiB |
nvidia-a100-80gb (x2) |
$1.70/hr |
g2-standard-32 |
32 |
128 GiB |
nvidia-l4 |
$1.85/hr |
a2-highgpu-2g |
24 |
170 GiB |
nvidia-tesla-a100 (x2) |
$3.20/hr |
g2-standard-48 |
48 |
192 GiB |
nvidia-l4 (x4) |
$3.40/hr |
a2-ultragpu-4g |
48 |
680 GiB |
nvidia-a100-80gb (x4) |
$3.40/hr |
a2-highgpu-4g |
48 |
340 GiB |
nvidia-tesla-a100 (x4) |
$6.40/hr |
ct5lp-hightpu-4t |
112 |
192 GiB |
ct5lp (x4) |
$6.60/hr |
ct5l-hightpu-4t |
112 |
192 GiB |
ct5l (x4) |
$6.60/hr |
g2-standard-96 |
96 |
384 GiB |
nvidia-l4 (x8) |
$6.80/hr |
a2-ultragpu-8g |
96 |
1.33 TiB |
nvidia-a100-80gb (x8) |
$6.80/hr |
a3-megagpu-8g |
208 |
1.83 TiB |
nvidia-h100-mega-80gb (x8) |
$12.40/hr |
a3-highgpu-8g |
208 |
1.83 TiB |
nvidia-h100-80gb (x8) |
$12.40/hr |
a2-highgpu-8g |
96 |
680 GiB |
nvidia-tesla-a100 (x8) |
$12.80/hr |
ct5lp-hightpu-8t |
224 |
384 GiB |
ct5lp (x8) |
$13.20/hr |
ct5l-hightpu-8t |
224 |
384 GiB |
ct5l (x8) |
$13.20/hr |
a2-megagpu-16g |
96 |
1.33 TiB |
nvidia-tesla-a100 (x16) |
$20.80/hr |
Instance type |
CPU |
Memory |
GPU |
Price* |
|---|---|---|---|---|
Standard_NC4as_T4_v3 |
4 |
28 GiB |
T4 |
$0.45/hr |
Standard_NC8as_T4_v3 |
8 |
56 GiB |
T4 |
$0.65/hr |
Standard_NV12ads_A10_v5 |
12 |
110 GiB |
A10 |
$0.85/hr |
Standard_NC16as_T4_v3 |
16 |
110 GiB |
T4 |
$1.05/hr |
Standard_NV18ads_A10_v5 |
18 |
220 GiB |
A10 |
$1.15/hr |
Standard_NC24ads_A100_v4 |
24 |
220 GiB |
A100 |
$1.45/hr |
Standard_NV36ads_A10_v5 |
36 |
440 GiB |
A10 |
$2.05/hr |
Standard_NV36adms_A10_v5 |
36 |
880 GiB |
A10 |
$2.05/hr |
Standard_NC48ads_A100_v4 |
48 |
440 GiB |
A100 |
$2.65/hr |
Standard_NC64as_T4_v3 |
64 |
440 GiB |
T4 |
$3.45/hr |
Standard_NV72ads_A10_v5 |
72 |
880 GiB |
A10 |
$3.85/hr |
Standard_NC96ads_A100_v4 |
96 |
880 GiB |
A100 |
$5.05/hr |
Standard_ND96asr_A100_v4 |
96 |
900 GiB |
A100 |
$5.05/hr |
Standard_ND96amsr_A100_v4 |
96 |
1.86 TiB |
A100 |
$5.05/hr |
Limits#
You can set cost controls for an entire Coiled workspace and for individual users within a workspace. This gives you fine control over how much users are able to spend each month.
See Managing resources for more details on workspace management and cost controls.
Avoid Idle Resources#
Idle timeout. Cloud resources take a couple minutes to spin up, so keeping them up is often desirable for ad hoc, interactive work. However, there’s usually a balance to strike between keeping cloud resources ready for rapid use and paying for idle hardware.
Coiled APIs have an idle_timeout parameter that can be used to control how long cloud resources can be idle before being automatically shut down.
@coiled.function(
idle_timeout="5 minutes", # Shutdown after 5 minutes of idleness
...
)
def predict(filename):
...
cluster = coiled.Cluster(
idle_timeout="10 minutes", # Shutdown after 10 minutes of idleness
...
)
$ coiled notebook start \
--idle-timeout "1 hour" # Shutdown after 1 hour of idleness
Adaptive Scaling. Coiled clusters and functions support adaptively scaling, or autoscaling, cloud resources up and down, depending on the size of the workload. This helps you scale up during compute intensive portions of a workflow, and then automatically scale down after work is completed. This helps avoid idle resources sitting around.
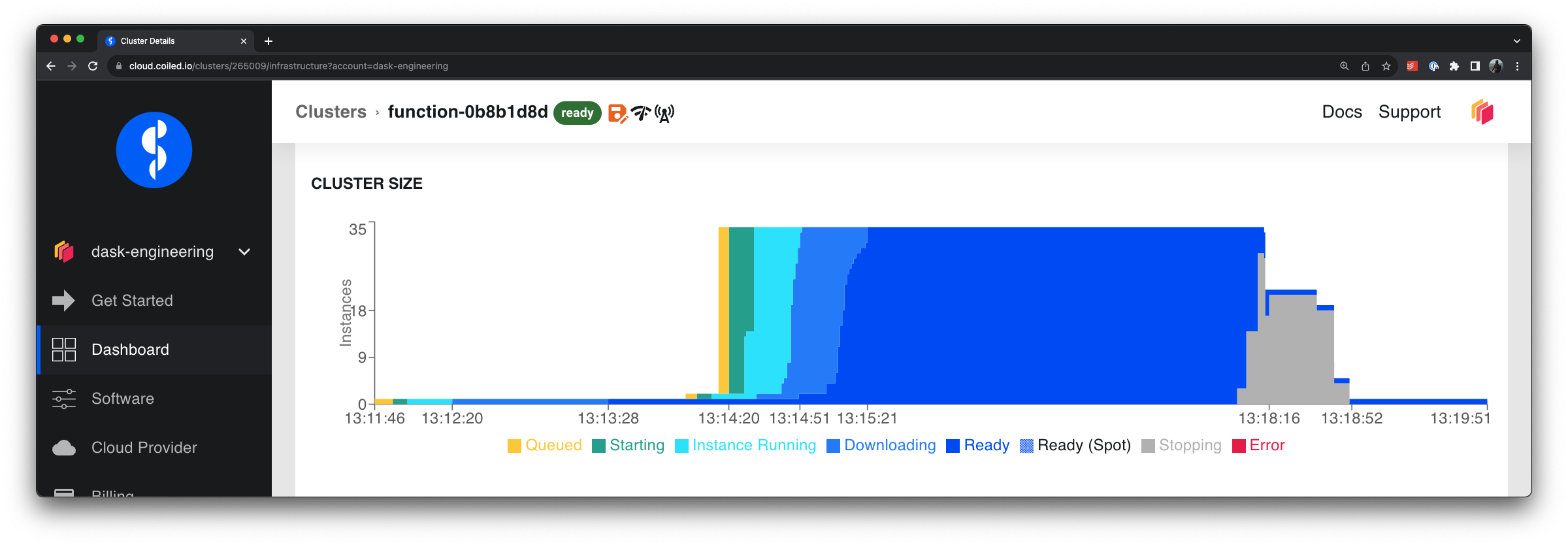
Cloud VMs adaptively scale up to process quickly in parallel and then scale down when work is done.#
Use Cases and Examples#
See the following for more concrete use cases and fully worked examples with GPUs in action on Coiled: