Why Coiled?#
At Coiled, we serve data developers on the cloud in two ways:
Smooth down development friction
Smooth down cost inefficiencies
We’re like a craftsman auto-mechanic who loves nothing more than the smooth hum of an engine, and a smooth grip on the steering wheel, except that our car is a fleet of cloud VMs. It’s a weird passion, granted, but it’s ours and we’re proud to own it.
This page steps outside of our normal documentation, and explains Coiled from a 10,000 foot view, explaining the why and how principles of Coiled. If you understand these things, you’ll understand the product as a whole.
Why Coiled: what principles drive the product
How Coiled: what technologies we’ve built to achieve these goals
Let’s start by talking about the why …
Why: Frictionless Development#
We love programming. It’s an art-form that’s pure creativity and structure. If you can think something then a few keystrokes later you can make it happen. Think back to the first time you played with Python. It felt like magic.

Originally published on https://xkcd.com/353#
Or at least it feels like magic when nothing gets in the way. Unfortunately, the cloud gets in the way a lot. The systems that have grown up around cloud computing are distastefully difficult, and for lack of a better word, un-ergonomic. The distance between thinking of a solution and having it in front of you is very far apart, often including weeks of development, fighting with frameworks and platforms, meetings with IT teams, and a general struggle of the soul.
And that’s a shame, because the cloud is awesome. Commanding a fleet of 1000 machines in concert feels amazing. Running those machines screaming at full tilt for five minutes to solve a massive problem, and then immediately turning them off for a total cost of only $1.66 feels like you’re cheating the devil. Everyone deserves to feel this power.
Why does the cloud have to be hard? Why do we need all of these systems to orchestrate it? Why do we need separate teams to manage the separate systems? The stack surrounding cloud computing needs to be stripped down and rebuilt until it’s fun to play with it, just like it was fun the first time you played with Python.
Why: Abundantly Cheap Computing#
The cloud is incredibly cheap. You can rent a computer that makes a billion calculations a second for $0.02 an hour. That machine can pull and process a terabyte of data from S3 for just ten cents.

When resources feel abundant we think about them differently. We think and act more creatively than when resources are scarce and our thinking narrows. With abundant and cheap resources our minds open, and we make better and more novel decisions.
But misuse stifles abundance#
Unfortunately, while the cloud can be incredibly cheap, it never is.
Cloud spend today is mostly through misuse, not overuse. It’s way too easy to misuse the cloud. The cloud is like a train; it’s incredibly efficient when it runs on the rails, but disastrous when it runs off those rails. Unfortunately the cloud’s “rails” don’t exist, so it’s easy for it to run off track.
We see the following costs very often among even very sophisticated customers:
S3 Egress costs ($0.10 per GB adds up quickly, and is 1000x the cost of compute)
Inter-Availability Zone traffic (same exact problem, but no one knows about it)
Leaving machines on because …
people don’t know how to turn them back on easily
ephemeral results are in memory
some job didn’t properly finish seven months ago
your data platform has a default 72 hour idle shutdown period (ahem, Databricks)
Network resources or storage drives are still allocated, even though machines are shut down
As a result, cloud bills climb, and budget holders step in and say “restrict cloud usage”. This is tragic, because abundant computation can create so much value so cheaply if only it’s used properly.
Abundance through efficiency#
The greatest joy in our job is seeing someone access hundreds of machines to do an overnight job in a few minutes. The next greatest joy is when they find out that it cost them $0.47. At that moment there’s a spark in their mind that says
I can do this as often as I like. I can go way bigger. Wait, my entire team can go bigger.
Ideas start racing. Old plans get replaced with more ambitious and transformative plans.
Abundant computing transforms how we work. Abundant computing transforms how we think.
Why: Infrastructure for Everyone#
Everyone should have access to abundant and easy computing, from engineers in the Fortune-500 to independent consultants and students.
This objective is baked into our company, from our open source roots, to the product’s onboarding flow, to the generous free tier (500 CPU hours free every month). We want Coiled to be like GitHub, a public good for society, while also a profitable enterprise when engaging companies with money.
Coiled endeavors to …
Be simple enough to set up and use without an IT team
Be free for modest use
Be solid and reliable indefinitely
How: Raw Cloud Architecture#
Today many platforms run frameworks on frameworks on frameworks. For example:
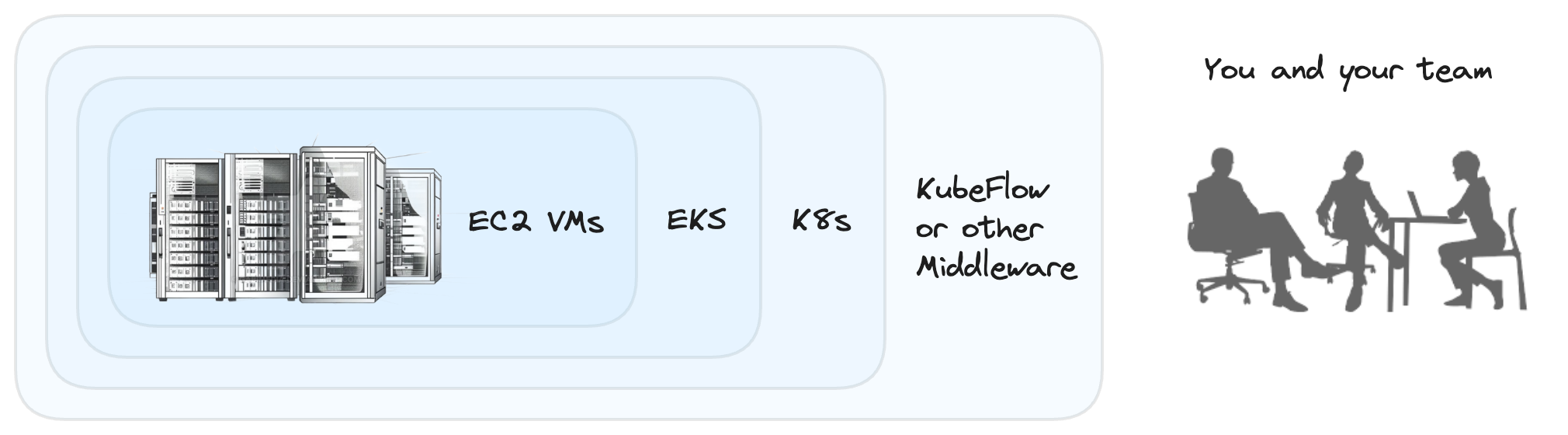
Instead, we run a far simpler stack, which we call a raw cloud architecture:
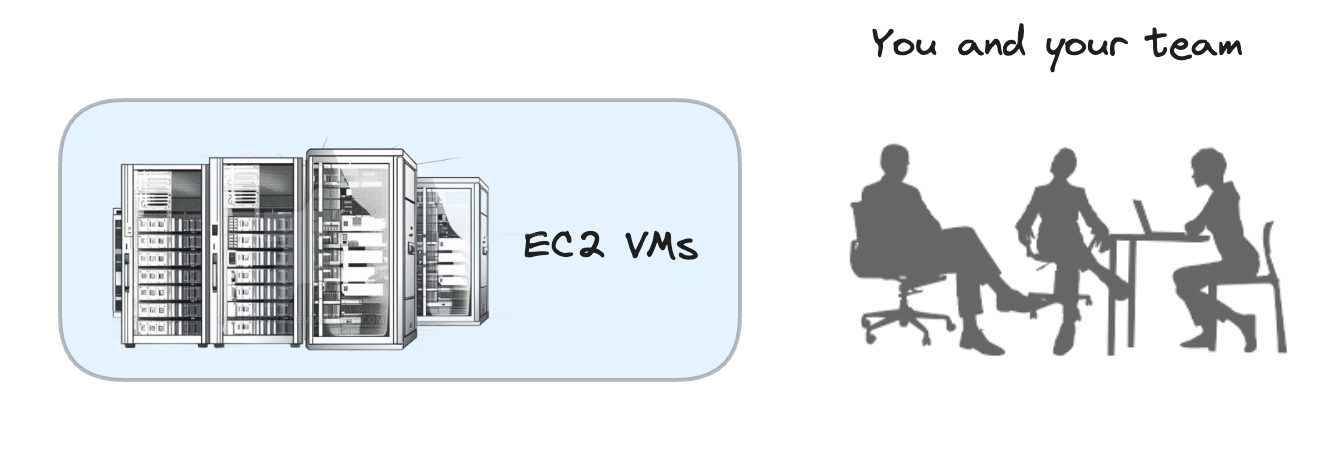
This is how that helps …
Problems with Layered Abstractions#
Every layer promises to hide abstractions, but delivers to you a new abstraction to learn instead. Unfortunately …
Leaky Abstractions: None of the layers completely covers the layer beneath, and so you always have to dig deep through layers and layers of logs when something goes wrong. (And something always goes wrong.)
Weak Abstractions: Each layer restricts what you can do, never giving you the full flexibility of the layer below
Sometimes these layers are exactly what you need. Do you need to run 18 high-availability services across multiple availability zones? Use Kubernetes for the love of god. Do you not need to do that? Well then Kuberentes might be overkill.
Most people we see just want to run jobs on cloud machines.
They want to run 1000 of those jobs at once.
They want to run jobs every hour.
They want to run jobs in different regions close to different data.
They want those jobs to use different languages or packages or binaries.
They want those jobs to use GPUs or fast disk.
Raw Cloud Architecture#
But in the end they just want to run jobs and for that, the stack you need is
Just EC2.
And that stack is really effing simple. It’s also really powerful. You can rent any kind of machine anywhere in the world with any speed or size of disk within a minute. That’s crazy! Can you imagine setting up a Kubernetes cluster that would let you do that? OMG the yaml you would need …
This is what we mean by “Raw Cloud Architecture”. We just use the raw APIs provided by the cloud providers for services that have been around forever. EC2 for compute, S3 for storage, etc.. This architecture is fantastic because …
It can be assembled on the fly in one minute anywhere in the world
It can be torn down immediately after use, leaving no lingering services
It is fully flexible, giving any choice of hardware instantly
It is brutally cheap
…
It’s really effing simple.
How: Environment Synchronization#
Coiled synchronizes your development environment and copies it on machines that it creates for you. This is a bigger deal than it seems on the surface.
Coiled copies …
Packages installed with conda, pip, poetry, uv, …
Local packages installed with
pip install -eAll
.pyfiles or development filesYour cloud data access credentials
Local environment variables that you select
…
On the surface this seems like just a handy feature. You get to stop building Docker images. But when we look deeper we realize that it’s really transformative to how people work.
On the Surface: No more docker build / docker push#
Q: How do I install a new package in my cloud environment
A: Just pip install locally and we’ll synchronize it automatically
Docker is fantastic if you want to build something once, and use it for the next ten years. We support Docker for exactly this use case.
Docker sucks if your environment changes every five minutes, which it does early on in data-oriented development lifecycles. Inserting a docker build / docker push / docker pull iteration every time you install a new package or update a script or a file adds friction, and goes against the goal of Frictionless Development.
Environment synchronization makes us faster and it makes us more likely to try out new software or new features that weren’t available the last time the production team updated the data science environment.
Going Deeper: Composability and Modularity#
But sharing the same development environment between our development machines and our cloud machines has loads of additional benefits. Consider the following questions and answers we often get / give:
Production configuration
Q: How do I ensure a consistent environment for my cloud computations?
A: How would you do this locally? A requirements.txt file? Poetry?Yeah, just keep doing that.
Third Party Integrations
Q: How do I use Coiled from Airflow? Do you have an integration?
A: You justimport coiledin your Airflow task. The “integration” is just Python
Q: How about GitHub Actions? Do you support webhooks?
A: Again, you can justimport coiledin your GitHub action and call it from thereIDE support
Q: Does your platform support VSCode/PyCharm/Jupyter?
A: Just keep using those tools however you’ve been using them. You don’t need to author your code on our platform.
You use Coiled as you would use any other library, and so it composes easily with other libraries and tools. The questions above are common, but also silly. We wouldn’t ask a tool like VSCode “can I import library X in VSCode?” or “can I develop Airflow code in PyCharm?”. We expect some systems to be composable (like VSCode) and we expect some systems to not be composable (like cloud platforms).
Why not? We should expect our platforms to compose with our tools and libraries. Composability enables the craft and creativity of programming to yield unplanned results.
However, cloud frameworks broke this expectation. Historical cloud frameworks (ahem Cloudera and Databricks) created nice little paths for users to follow like “notebooks” and “scheduled jobs” that were convenient but limiting. Canned experiences like these are easy onramps to a world without creativity. They lack inspiration.
It’s easy to use Coiled from anywhere with the same tooling you use today. Coiled doesn’t just move your code to the Cloud, it moves the context around that code. Copying and moving around the development context between dev and cloud has benefits that even we didn’t expect like …
It’s trivial to experiment with new architectures like ARM
It’s trivial to switch from PyTorch on Mac to PyTorch on GPU machines
You don’t need to worry about keeping different systems in sync (the souce of 90% of bugs)
…
And we’re finding more every day.
Coiled’s Environment Synchronization enables you to compose cloud computing with general programming in a way that unburdens developers, and yields surprising results.
How: Direct Feedback Engineering Culture#
Coiled collects deep telemetry to give our engineers direct feedback about user experience.
Every company does this to some extent; but Coiled differs in two important ways:
Direct feedback: The user<->engineer feedback is direct, and not mediated by layers of customer success / product managers / sales
Machine + Python metrics: Our telemetry combines cloud infrastructure metrics and Python-specific metrics, and so covers the intersection of machine performance and human performance
Direct feedback#
When your machine goes down, we’re alerted (this is tablestakes). When your code throws an error, we’re alerted. When your clusters are idling or thrashing, we’re alerted. These alerts go directly to engineers. Not to a sales team, or to a product manager. Our engineering culture is centered on tight unfiltered feedback from direct user experience.
Other companies: user <-> Support team <-> Product manager <-> Engineering manager <-> engineers
Us: Users <-> automated systems <-> engineers
This is how we make a delightful product.
And the result is that …
When failures occur (and failures always occur) we reach out quickly (often before you realize something is wrong)
The people who reach out are really knowledgeable engineers
Product is delightful, and gets more delightful day-by-day in ways that affect you
Machine + Python Metrics#
Because Coiled combines cloud infrastructure and Python development we go deeper into your computation than tools like Datadog / log aggregators / system metrics. By incorporating Python metrics and context we’re to learn not just from how your machines are doing, but also how your libraries and how your people are doing. This intersection of human-machine performance is core to achieving both frictionless development, and abundant and efficient computing.