Dec 17, 2024
2m read
Faster Xarray Quantile Computations with Dask#
Patrick Hoefler
There have been a number of engineering improvements to Dask Array like consistent chunksizes in Xarray rolling-constructs and improved efficiency in map_overlap. Notably, as of Dask version 2024.11.2, calculating quantiles is much faster and more reliable.
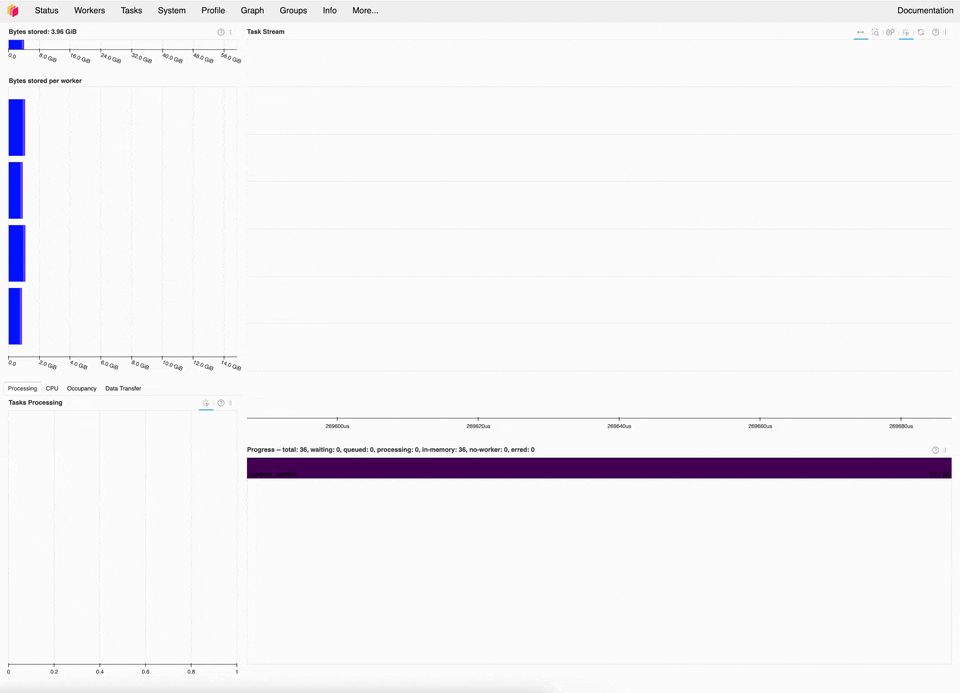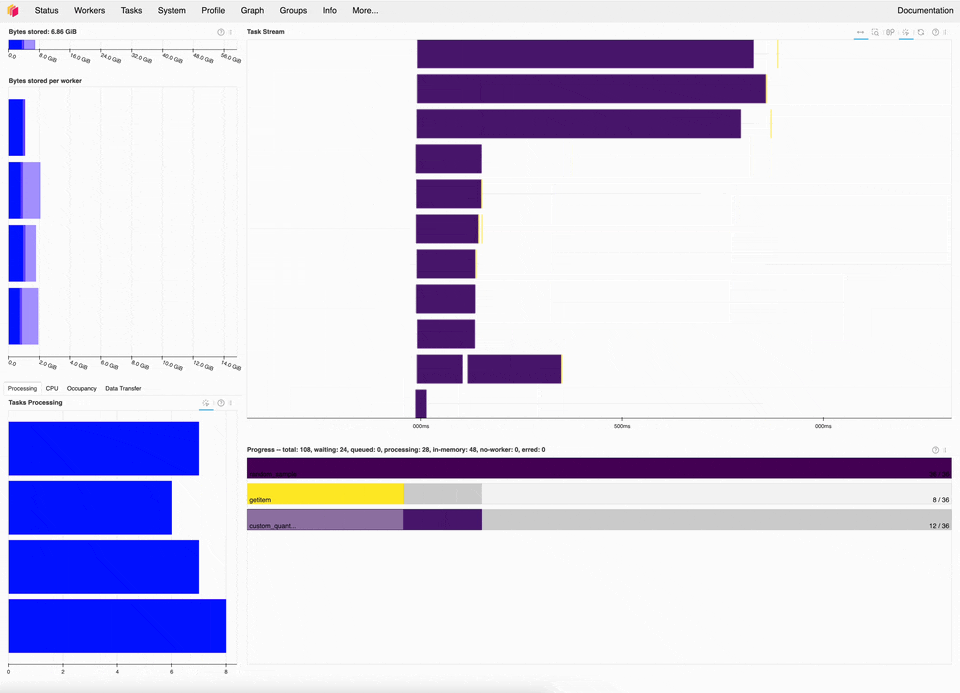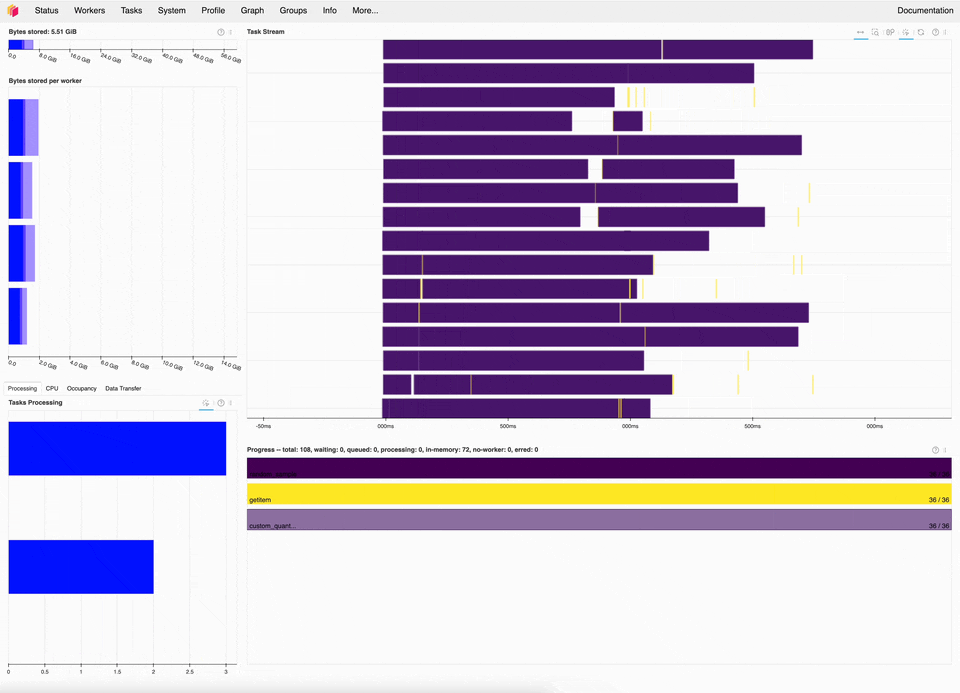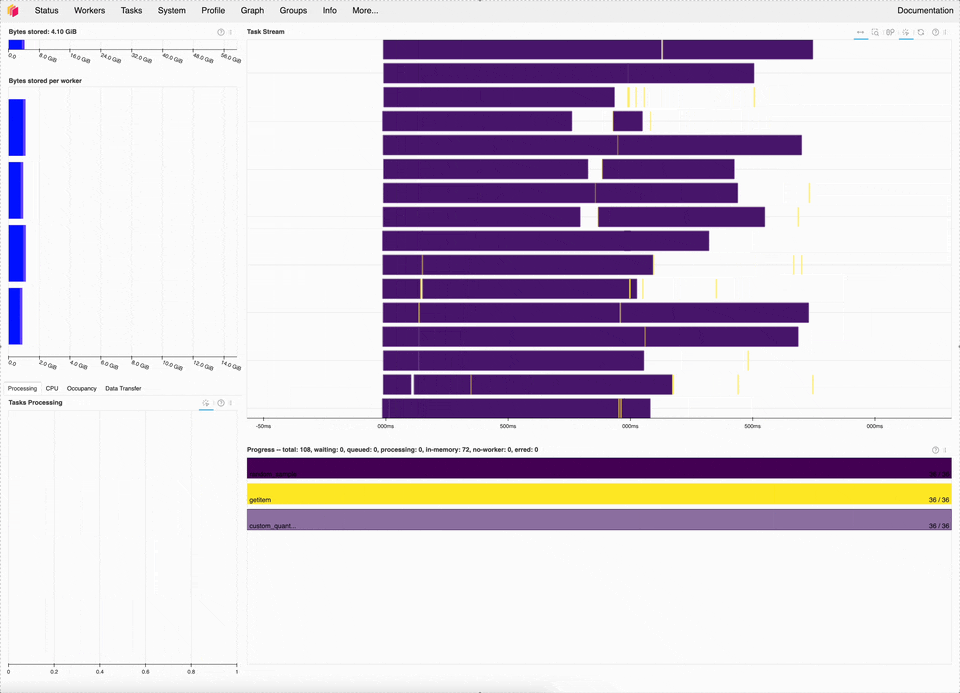
Dask dashboard of the new quantile implementation, which is ~20x faster for this microbenchmark.#
Calculating Quantiles with Xarray#
Calculating quantiles is a common operation for geospatial data. Quantiles show how a dataset is distributed over time, allowing you to identify trends, anomalies, and variation within specific grid cells or regions. These calculations are typically performed either for distinct groups within the dataset or across the dataset as a whole.
The Problem: np.quantile Can Be Slow#
The data we often encounter typically has a relatively short time axis, consisting of only a few hundred to a few thousand values, while the latitude and longitude dimensions are extensive.
Previously, the quantile calculation for every coordinate was done on a pretty small array with the NumPy implementation np.quantile or np.nanquantile:
import numpy as np
np.quantile(np.random.randn(500), q=0.5)
Dask lacked an efficient efficient multidimensional implementation for calculating quantiles, which meant calling the one-dimensional NumPy implementation millions of times in Python. This is very slow and also blocks the GIL (looking forward to a free-threaded Python world 😅). This caused large slowdowns on workers with more than one thread and could lead to runtimes over 200s per chunk.
Running the following computation previously took over 3 minutes to complete:
import xarray as xr
import dask.array as da
arr = da.random.random((50, 3_000, 3_000), chunks=(-1, "auto", "auto"))
darr = xr.DataArray(
arr, dims=["time", "x", "y"]
)
darr.quantile(dim="time", q=0.75).compute()
The Solution: A New dask.array.quantile#
As of dask=2024.11.2, we’ve added a high-level quantile API to Dask that uses top level NumPy functions to extract the quantile for each time slice. The operations are more expensive than an optimal quantile implementation, but the vectorized, multidimensional nature of each call makes it a lot faster in aggregate. And we don’t block the GIL anymore, so you can run with proper parallelism on your Dask workers.
The new quantile implementation reduces runtime to ~1s per chunk, independent of the number of threads. This means we’re able to calculate quantiles hundreds of times faster than before! You can expect the speedups to scale with the size of your quantile axis.
You can try out the new implementation by upgrading to the latest versions of Dask and Xarray.
conda update dask xarray
pip install --upgrade "dask[complete]" xarray
For other recent improvements to using Xarray with Dask, you might consider: