Dask and the PyData Stack#
TL;DR#
The PyData stack for scientific computing in Python is an interoperable collection of tools for data analysis, visualization, statistical inference, machine learning, interactive computing and more that is used across all types of industries and academic research. Dask, the open source package for scalable data science that was developed to meet the needs of modern data professionals, was born from the PyData community and is considered foundational in this computational stack. This post describes a schematic for thinking about the PyData stack, along with detailing the technical, cultural, and community forces that led to Dask becoming the go-to package for scalable analytics in Python, including its interoperability with packages such as NumPy and pandas, among many others.
The Python Data Science Stack#
In 2017, Jake VanderPlas gave a keynote at PyCon called “The Unreasonable Effectiveness of Python in Science”, in which he presented a schematic of the scientific Python stack, also commonly referred to as the PyData stack. This is a broad collection of Python packages used for scientific computing and data science, in both industry and basic research:
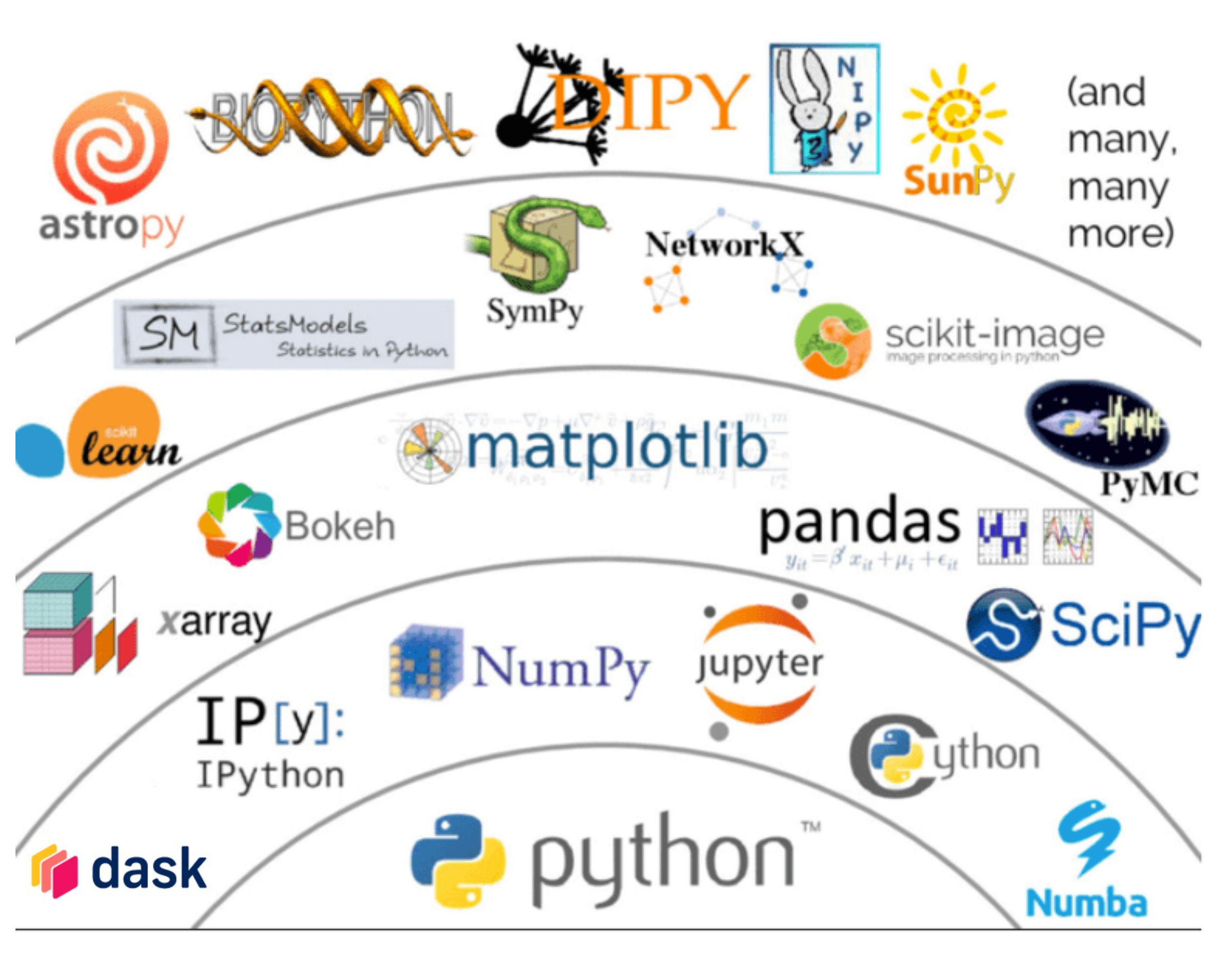
At the bottom of the stack, you have the Python standard library. As you move out, the next layer extends Python in ways that are useful to scientists and foundational for data science in Python, such as
NumPy for numerical array computing,
Project Jupyter and IPython for interactive computing and IDEs,
Numba for just-in-time compilation, and
Dask for scaling your data science to larger datasets and larger models.
Jake stated that “built on top of this layer are tools that are slightly more specialized”, such as matplotlib and bokeh for data visualization, pandas for data ingestion and wrangling, Xarray for multidimensional labelled structures (these, as Jake made clear, depend on the level below them, and are “higher level tools”).
Moving up to even higher level tools, we discover scikit-learn for machine learning, statsmodels for statistical modeling, and PyMC for Bayesian inference and probabilistic programming, among others. On top of these, you have field-specific packages like astropy and biopython (for astronomy and biology, respectively).
Dask is Foundational in the PyData stack#
If you’re asking “Why is Dask foundational in the PyData stack?”, you’re asking a great question. The answer is: because it composes well with all of the PyData tools. It’s a simple system designed to parallelize any PyData library. This means that, if you’re looking to natively scale up your Python code to larger datasets within the PyData ecosystem, you’ll be using Dask. One result of this is the elegance of the Dask API:
if you’re writing Dask code to scale your NumPy code, what you write will mimic the NumPy API, providing a smooth transition;
Similarly, if you’re writing Dask code to scale your pandas code, what you write will mimic the pandas API.

Dask arrays scale Numpy workflows, enabling multi-dimensional data analysis in earth science, satellite imagery, genomics, biomedical applications, and machine learning algorithms (from the Dask documentation).
Matt Rocklin, creator of Dask and CEO of Coiled, once said to me:
People really like that Dask Array follows the NumPy API almost exactly. Dask DataFrame follows the Pandas API almost exactly. Dask-ML follows the scikit-learn API almost exactly. There are definitely differences but those differences are necessary because there are some things you do need to think about in parallel algorithms. The Dask maintainers have written a lot of Python data science code and we’re actually the maintainers of all those other libraries too. So it’s rare to find someone who understands NumPy and won’t be able to transition on their own to Dask Array. There’s a very smooth transition process between all the different systems.
As an example, compare the following NumPy and Dask code chunks, noticing how you use NumPy syntax when working with your Dask array:
import numpy as np
x = np.random.random((1000, 1000)) # Create array of random numbers
y = x + x.T # Add x to its transpose
z = y[::2, 500:].mean(axis=1) # Compute mean of a slice of Y
import dask.array as da
x = da.random.random((10000, 10000), chunks=(1000, 1000)) # Create Dask array
y = x + x.T # Add x to its transpose
z = y[::2, 5000:].mean(axis=1) # Compute mean of a slice of Y
Not only is the end-user programming experience of a Dask Array (or DataFrame) “like” the NumPy or Pandas equivalent, it actually delegates to NumPy (or pandas) code running against real NumPy (or pandas) objects as much as possible. Why is this important? It means, for example, that pandas users’ mental model of what’s happening is close and, in some cases, identical to what actually runs, making a user more productive with less work. By contrast, some other tools – like Koalas (a wrapper over Spark) – imitate the Pandas API but delegate to vastly different machinery underneath. In the case of Spark, the real challenge is understanding enough of that machinery to work with it well, and Koalas can make a tough situation even harder, by hiding the traps and pitfalls until a user falls in.
This consistency of Dask with the PyData is both (1) by design and (2) a result of cultural and community forces. With respect to the design of Dask, there were several technical and social goals for Dask:
Technical: Harness the power of all of the cores on the laptop/workstation in parallel;
Technical: Support larger-than-memory computation, allowing datasets that fit on disk, but not in RAM;
Social: Invent nothing. We wanted to be as familiar as possible to what users already knew.
Sociotechnical: Dask was designed to be lightweight technically so that it could be integrated into other Python libraries.
Now let’s dive into the cultural and community forces that led to the simplicity of Dask’s API.
The Dask Community IS the PyData Community#
In terms of cultural and community forces, Dask was developed by members of the Python data science community for Pythonista data scientists. Moreover, the Dask developer community is the PyData community:
Stefan Hoyer, the creator of Xarray, hooked up Dask and Xarray in around two weeks;
Min Ragan-Kelly, from Project Jupyter and IPython parallel, and Olivier Grisel, from Scikit-Learn & Joblib, helped to build the current incarnation of the dask-distributed scheduler;
The original idea for Dask arose at Anaconda Inc. (the company that built the popular Anaconda distribution, along with many other open source tools) from conversations and work with founders Peter Wang and Travis Oliphant, the former of whom created the PyData conference series, the latter of whom created NumPy in 2005!
Tom Augspurger is a core maintainer of both Pandas and Dask so when Tom makes features in Pandas, he also makes them in Dask.
These are a mere handful of examples and there are many more. The cultural and the technical aspects of any design system are interwoven. Due to the social and technical forces outlined here, a key differentiator of Dask in the scalable data science world is that it is Python top-to-bottom: it’s Python all the way down! For high-level API calls, we may not care what’s underneath. But when we need extensibility, flexibility, and support for custom use cases, non-Pythonic abstractions such as PySpark tend to leak heavily. Many Pythonistas have gotten burned trying to use PySpark, thinking it’s a Python library, only to discover Python is a minimal veneer over a complex Scala and Java system lacking Pythonic behaviors.
The PyData stack is more than a collection of disparate packages created and maintained by different people. It is, rather, a collection of interoperable tools and packages for data science developed by a community (a cool data science project would be a network analysis of PyData stack contributors and packages, using publicly available github data). And the way to scale your data science while staying in this ecosystem is by using Dask.

Dask DataFrames scale Pandas workflows, enabling applications in time series, business intelligence, and general data munging on big data (from the Dask documentation).
Learn More#
To learn more about Dask and what we’re working on at Coiled to help meet the needs of teams and the enterprise in scaling data science, analytics, and machine learning, sign up to our email list below. We’ll also be writing more posts in the future about how Dask integrates with NumPy, pandas, popular machine learning such as scikit-learn and xgboost, and deep learning frameworks, including PyTorch and tensorflow so keep your eyes peeled for them!