High Level Query Optimization in Dask#
Introduction#
Dask DataFrame doesn’t currently optimize your code for you (like Spark or a SQL database would). This means that users waste a lot of computation. Let’s look at a common example which looks ok at first glance, but is actually pretty inefficient.
import dask.dataframe as dd
df = dd.read_parquet(
"s3://coiled-datasets/uber-lyft-tlc/", # unnecessarily reads all rows and columns
)
result = (
df[df.hvfhs_license_num == "HV0003"] # could push the filter into the read parquet call
.sum(numeric_only=True)
["tips"] # should read only necessary columns
)
We can make this run much faster with a few simple steps:
df = dd.read_parquet(
"s3://coiled-datasets/uber-lyft-tlc/",
filters=[("hvfhs_license_num", "==", "HV0003")],
columns=["tips"],
)
result = df.tips.sum()
Currently, Dask DataFrame wouldn’t optimize this for you, but a new effort that is built around logical query planning in Dask DataFrame will do this for you. This article introduces some of those changes that are developed in dask-expr.
You can install and try dask-expr with:
pip install dask-expr
We are using the NYC Taxi dataset in this post.
Dask Expressions#
Dask expressions provides a logical query planning layer on top of Dask DataFrames. Let’s look at our initial example and investigate how we can improve the efficiency through a query optimization layer. As noted initially, there are a couple of things that aren’t ideal:
We are reading all rows into memory instead of filtering while reading the parquet files.
We are reading all columns into memory instead of only the columns that are necessary.
We are applying the filter and the aggregation onto all columns instead of only
"tips".
The query optimization layer from dask-expr can help us with that. It will look at this expression
and determine that not all rows are needed. An intermediate layer will transpile the filter into
a valid filter-expression for read_parquet:
df = dd.read_parquet(
"s3://coiled-datasets/uber-lyft-tlc/",
filters=[("hvfhs_license_num", "==", "HV0003")],
)
result = df.sum(numeric_only=True)["tips"]
This still reads every column into memory and will compute the sum of every numeric column. The
next optimization step is to push the column selection into the read_parquet call as well.
df = dd.read_parquet(
"s3://coiled-datasets/uber-lyft-tlc/",
columns=["tips"],
filters=[("hvfhs_license_num", "==", "HV0003")],
)
result = df.sum(numeric_only=True)
This is a basic example that you could rewrite by hand. Use cases that are closer to real workflows might potentially have hundreds of columns, which makes rewriting them very strenuous if you need a non-trivial subset of them.
Let’s take a look at how we can achieve this. dask-expr records the expression as given by the
user in an expression tree:
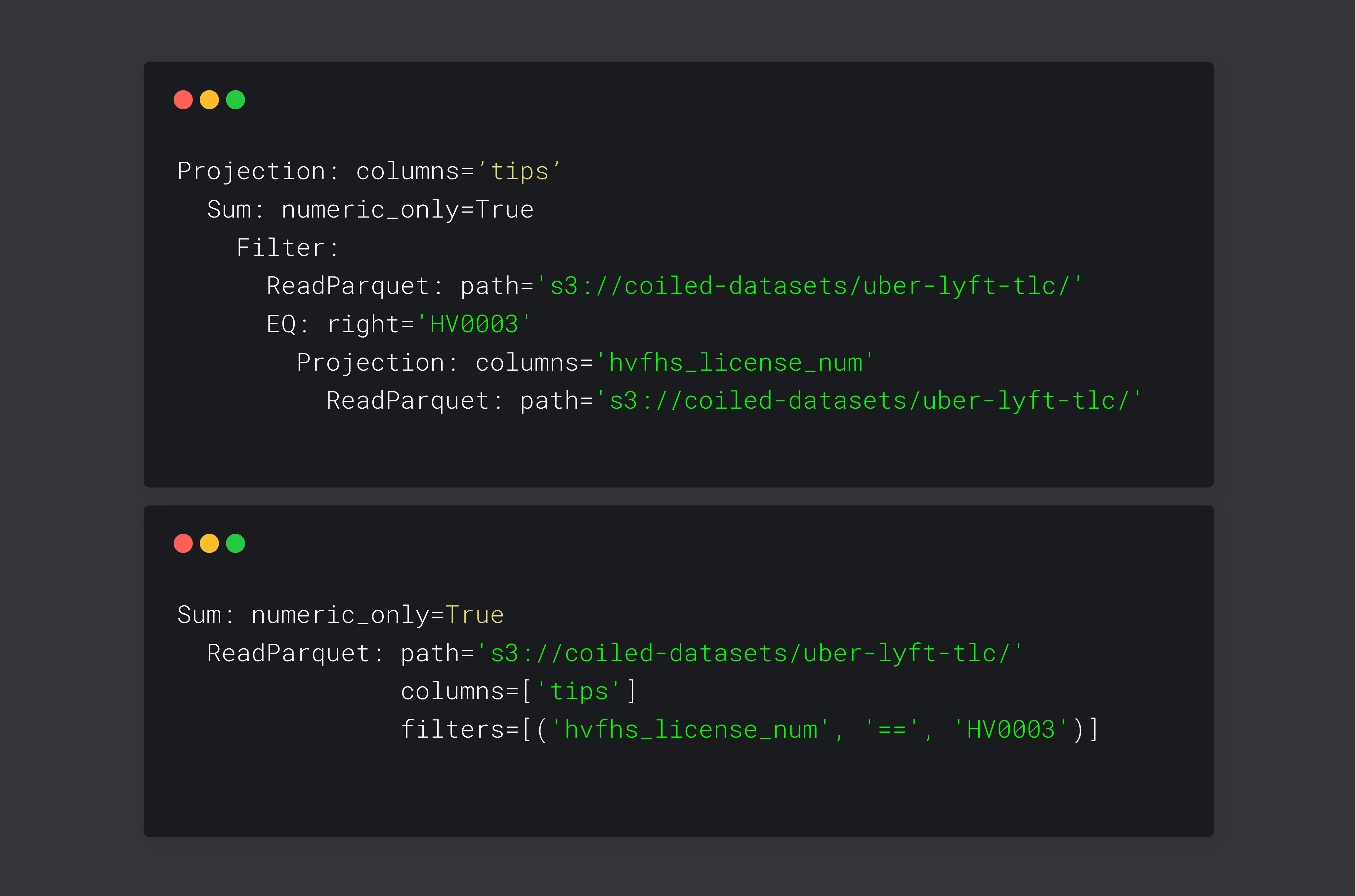
result.pprint()
Projection: columns='tips'
Sum: numeric_only=True
Filter:
ReadParquet: path='s3://coiled-datasets/uber-lyft-tlc/'
EQ: right='HV0003'
Projection: columns='hvfhs_license_num'
ReadParquet: path='s3://coiled-datasets/uber-lyft-tlc/'
This tree represents the expression as is. We can observe that we would read the whole dataset into memory before we apply the projections and filters. One observation of note: It seems like we are reading the dataset twice, but Dask is able to fuse tasks that are doing the same to avoid computing these things twice. Let’s reorder the expression to make it more efficient:
result.simplify().pprint()
Sum: numeric_only=True
ReadParquet: path='s3://coiled-datasets/uber-lyft-tlc/'
columns=['tips']
filters=[('hvfhs_license_num', '==', 'HV0003')]
This looks quite a bit simpler. dask-expr reordered the query and pushed the filter and the column
projection into the read_parquet call. We were able to remove quite a few steps from our expression
tree and make the remaining expressions more efficient as well. This represents the steps that
we did manually in the beginning. dask-expr performs these steps for arbitrary many columns without
increasing the burden on the developers.
These are only the two most common and easy to illustrate optimization techniques from dask-expr.
Some other useful optimizations are already available:
len(...)will only use the Index to compute the length; additionally we can ignore many operations that won’t change the shape of a DataFrame, like areplacecall.set_indexandsort_valueswon’t eagerly trigger computations.Better informed selection of
mergealgorithms.…
We are still adding more optimization techniques to make Dask DataFrame queries more efficient.
Try it out#
The project is in a state where interested users should try it out. We published a couple of releases. The API covers a big chunk of the Dask DataFrame API, and we keep adding more. We have already observed very impressive performance improvements for workflows that would benefit from query optimization. Memory usage is down for these workflows as well.
We are very much looking for feedback and potential avenues to improve the library. Please give it a shot and share your experience with us.
dask-expr is not integrated into the main Dask DataFrame implementation yet. You can install it
with:
pip install dask-expr
The API is very similar to what Dask DataFrame provides. It exposes mostly the same methods as Dask DataFrame does. You can use the same methods in most cases.
import dask_expr as dd
You can find a list of supported operations in the Readme. This project is still very much in progress. The API might change without warning. We are aiming for weekly releases to push new features out as fast as possible.
Why are we adding this now?#
Historically, Dask focused on flexibility and smart scheduling instead of query optimization. The distributed scheduler built into Dask uses sophisticated algorithms to ensure ideal scheduling of individual tasks. It tries to ensure that your resources are utilized as efficient as possible. The graph construction process enables Dask users to build very flexible and complicated graphs that reach beyond SQL operations. The flexibility that is provided by the Dask futures API requires very intelligent algorithms, but it enables users to build highly sophisticated graphs. The following picture shows the graph for a credit risk model:

The nature of the powerful scheduler and the physical optimizations enables us to build very complicated programs that will then run efficiently. Unfortunately, the nature of these optimizations does not enable us to avoid scheduling work that is not necessary. This is where the current effort to build high level query optimization into Dask comes in.
Conclusion#
Dask comes with a very smart distributed scheduler but without much logical query planning. This is something we are rectifying now through building a high level query optimizer into Dask DataFrame. We expect to improve performance and reduce memory usage for an average Dask workflow.
This API is read for interested users to play around with. It covers a good chunk of the DataFrame API. The library is under active development, we expect to add many more interesting things over the coming weeks and months.