Sept. 5, 2025
6 min read
How to run pandas on GPUs with Coiled#
Pandas is the go-to library for data manipulation and analysis in Python, but it struggles with large datasets due to its single-threaded, CPU-bound design. As data grows in size and complexity, analysts and data scientists often face slow processing times and memory bottlenecks that interrupt analytical flow and limit business responsiveness.
Traditional pandas is single-threaded and CPU-bound, which makes it great for prototyping but increasingly inefficient for large-scale data work. By offloading operations to parallel GPU cores, you can accelerate pandas-like workflows without rewriting your entire codebase. Accessing GPUs can be challenging, though. Most people don’t have NVIDIA GPUs locally, so they need cloud GPUs. This typically involves complex cloud setup, IAM configuration, Docker images, infrastructure maintenance, and cost management.
With tools like RAPIDS cuDF and Coiled, it’s possible to scale these workloads easily and access GPU acceleration with minimal code changes.
In this article, you’ll learn how to:
Accelerate pandas operations using cuDF with minimal code changes
Easily access cloud GPUs with Coiled
Achieve dramatic performance improvements on real datasets
Determine whether GPU-acceleration might be a good fit for your workflow
Why GPU-accelerated pandas delivers faster performance#
Many data analysis tasks on large datasets are well-suited for GPU acceleration. Embarrassingly parallel operations like filtering, element-wise mappings, and reductions can be run in parallel on a GPU rather than sequentially, resulting in dramatically shorter computation times.
GPU-accelerated pandas operations can achieve performance improvements of 10-150x compared to CPU-only processing. Real-world benchmarks demonstrate these dramatic speedups:
H2O.ai Database-like Ops Benchmark: 150x faster processing on 5GB datasets with complex joins and group-by operations
NYC ride-share analysis: 8.9x faster execution time on 64.8 million records
By leveraging GPU capabilities, data scientists and analysts can:
Process larger datasets without hitting memory limitations
Run transformations and calculations significantly faster
Iterate more quickly on data exploration and model development
How Coiled simplifies GPU access#
Despite the performance advantages of GPUs, accessing cloud GPU resources often requires complex infrastructure setup, specialized cloud configuration, and significant DevOps expertise. Coiled eliminates these barriers by making cloud GPUs accessible to anyone with basic Python skills, removing the need for specialized hardware investments or cloud infrastructure management.
The Coiled platform removes common barriers to GPU computing, including:
Hardware acquisition costs
Complex cloud infrastructure configuration
Driver compatibility issues
DevOps expertise requirements
Resource provisioning and scaling complexity
Example: How often do New Yorker’s tip?#
To see how to use Coiled for GPU-accelerated pandas in practice, we’ll look at a subset of Uber and Lyft rides in New York City over the last several years and perform some simple calculations.
Sign up#
First, we sign up for Coiled using GitHub, Google, or by making our own username and password.
Install Coiled#
Next, we’ll install Coiled.
$ pip install coiled
$ coiled login
This will redirect us to the Coiled website to authenticate our computer. It will also save our Coiled token on our computer.
Create a GPU-enabled software environment#
By default, Coiled automatically copies our local environment to remote VMs. However, if we do not have an NVIDIA GPU available locally, then we need to create a software environment or use the RAPIDS Docker container (see the RAPIDS installation guide).
To define a software environment, we define the dependencies in a conda environment YAML file:
channels:
- rapidsai
- conda-forge
- nvidia
dependencies:
- python=3.12
- rapids>=25.1
- cuda-version>=12.0,<=12.9
- s3fs
- jupyterlab
And then create a Coiled software environment:
coiled env create --name rapids --gpu-enabled --conda rapids-env.yaml
Launch a GPU-enabled Jupyter Notebook#
Next, we start a JupyterLab instance on a GPU-enabled VM on the cloud:
coiled notebook start --gpu --software rapids
Under the hood, Coiled handles:
Provisioning a cloud VM with GPU hardware. In this case, a
g4dn.xlarge(Tesla T4) instance on AWS.Downloading the software environment onto the VM
Tearing everything down once you’re done (no idle costs)
We could also include additional arguments like:
--syncto live-sync local files, including Jupyter Notebooks, to the cloud machine. Any changes made in the notebook running remotely will be synchronized back to our computer. We need to install Mutagen for that.--vm-typeto request a specific VM type.--regionto specify a region. We find GPUs are often easier to get in AWS region us-west-2.
See the Coiled notebooks documentation for more details.
Running GPU-accelerated cudf.pandas#
NVIDIA RAPIDS offers GPU acceleration for data science workloads with minimal code changes. The cudf.pandas accelerator enables instant GPU execution of pandas operations by loading the extension with: %load_ext cudf.pandas.
We adapted this example from the RAPIDS documentation. We’ll look at a subset of the NYC taxi dataset (~60 million rows) and calculate how often New Yorkers tip.
%load_ext cudf.pandas
import pandas as pd
import s3fs
path_files = []
for i in range(660,715):
path_files.append(pd.read_parquet(f"s3://coiled-data/uber/part.{i}.parquet", storage_options={"anon": True}))
df = pd.concat(path_files, ignore_index=True)
df["tipped"] = df["tips"] != 0
df["tip_frac"] = df["tips"] / (df["base_passenger_fare"] + df["tolls"] + df["bcf"] + df["sales_tax"] + df["congestion_surcharge"].fillna(0) + df["airport_fee"].fillna(0))
df["service"] = df["hvfhs_license_num"].map({
"HV0003": "uber",
"HV0005": "lyft",
"HV0002": "juno",
"HV0004": "via",
})
df = df.drop(columns="hvfhs_license_num")
df["tipped"].mean()
We can monitor GPU utilization from the Coiled dashboard as the code runs (and afterwards too):
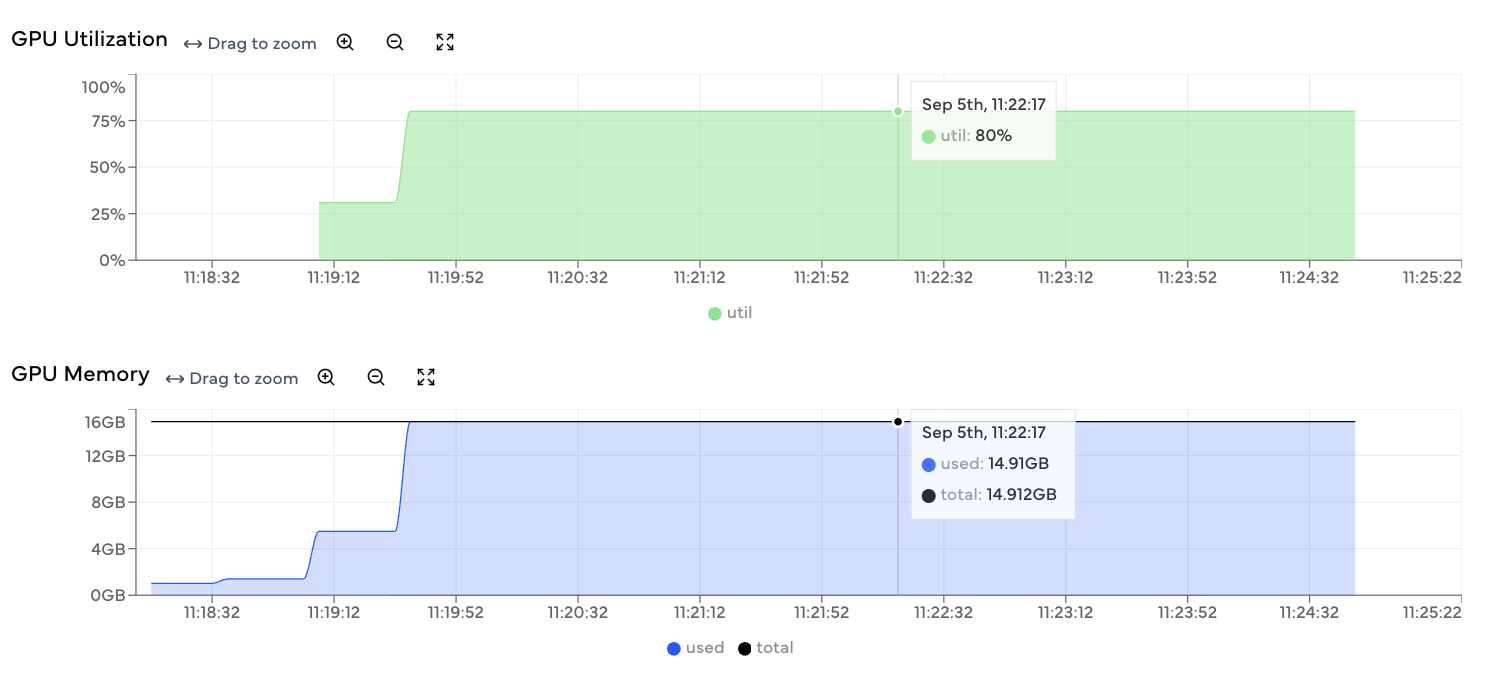
Run a Python script on a cloud GPU#
While Jupyter Notebooks are helpful for interactive workflows, there are a number of ways we can use Coiled to access GPUs. In particular, Coiled Batch is an easy way to run any script on the cloud. It is especially useful for scaling large, independent tasks (ie, embarrassingly parallel workloads) across hundreds of VMs.
We could run the same analysis as above by adding the following metadata to the top of the script:
my_script.py## COILED gpu True
# COILED software rapids
# COILED region us-east-2
import pandas as pd
import s3fs
path_files = []
for i in range(660,715):
path_files.append(pd.read_parquet(f"s3://coiled-data/uber/part.{i}.parquet", storage_options={"anon": True}))
df = pd.concat(path_files, ignore_index=True)
df["tipped"] = df["tips"] != 0
df["tip_frac"] = df["tips"] / (df["base_passenger_fare"] + df["tolls"] + df["bcf"] + df["sales_tax"] + df["congestion_surcharge"].fillna(0) + df["airport_fee"].fillna(0))
df["service"] = df["hvfhs_license_num"].map({
"HV0003": "uber",
"HV0005": "lyft",
"HV0002": "juno",
"HV0004": "via",
})
df = df.drop(columns="hvfhs_license_num")
df["tipped"].mean()
and then launch the script with the following command, using the RAPIDS CLI to use cudf.pandas:
coiled batch run python -m cudf.pandas my_script.py
Under the hood Coiled will:
Spin up appropriate machines as defined by
# COILEDcommentsDownload the specified software environment
Run the script
Shut down the machines
In this example, we’re running a single Python script, but Coiled Batch especially excels at easily scaling large embarrassingly parallel jobs, without the scheduler overhead of tools like Dask. Some common use cases include:
Running an arbitrary bash script 100 times in parallel
When to use GPU acceleration#
While GPUs can offer impressive speedups, they’re not always the right choice, and there’s some nuance to using them well. Some general guidelines include:
1. Minimize memory transfers
Avoid moving data back and forth between CPU and GPU repeatedly
The PCIe bus transfer time can dominate your computation time
For small datasets with simple operations, this transfer overhead can make GPU processing slower than CPU
2. Maximize operational intensity
Choose problems that do lots of computation on relatively small amounts of data
Good fit: Matrix multiplication (O(n³) operations on O(n²) data)
Poor fit: Simple string matching (O(n) operations on O(n) data)
Use roofline analysis: memory-bound operations may not benefit from GPU acceleration
3. Don’t launch lots of small kernels
Avoid operations that create thousands of tiny CUDA kernels
Each kernel launch has overhead - many small operations can be slower than fewer large ones
Let optimized libraries like cuDF handle the kernel management
Kaashif Hymabaccus gave a detailed talk on this topic at PyCon US.
FAQs#
Can you run pandas on a GPU?
Traditional pandas cannot run directly on a GPU, but RAPIDS cuDF offers a nearly identical API that executes on GPU hardware.
What is the fastest way to run pandas on GPUs?
The fastest way to run pandas on GPUs is by using RAPIDS cuDF with the cudf.pandas accelerator. It requires minimal code changes and can achieve up to 150x speedup on analytics workloads. You can scale this further using Dask-cuDF for multi-GPU processing and manage GPU clusters easily with Coiled’s cloud platform.
How do I set up Coiled for GPU-accelerated pandas workflows?
To use Coiled for GPU workloads, install Coiled via pip/conda/uv and launch a GPU-enabled cluster. Coiled handles all cloud provisioning, GPU drivers, and scaling. See the Coiled documentation on GPUs to learn more.
When should I use GPU acceleration for pandas workflows?
Consider using GPU acceleration for:
Large datasets with high computational intensity: There is some overhead with copying data to the GPU, so your data must be sufficiently large to offset this cost.
Matrix operations and linear algebra: Operations that scale as O(n²) or O(n³) with input size
Parallel aggregations: Group-by operations on large datasets with many groups (where data shuffling isn’t required)
Batch processing: You can process multiple operations together rather than one at a time
When should I stick with a CPU for pandas workflows?
GPU acceleration may actually hurt performance when:
Small datasets: Transfer overhead dominates computation time
Simple operations: String searches, basic filtering, or operations with low computational intensity
Memory-bound problems: Operations limited by memory bandwidth rather than compute capacity
Frequent CPU-GPU transfers: Workflows that require moving data back and forth repeatedly