May 5, 2023
4m read
How well does Dask run on Graviton?#
ARM-based processors are known for matching performance of x86-based instance types at a lower cost, since they consume far less energy for the same performance. It’s not surprising then that some companies, like Honeycomb, are switching their entire infrastructure to ARM.
We ran a number of Dask workloads on both x86- and ARM-based instance types and found costs were typically 20-30% lower when using ARM. We also tested out the latest generation of Amazon’s ARM-based processors Graviton3 instance types and looked at performance for a compute-heavy workload using Dask and XGBoost.
AWS Graviton#
Intel designs all Intel chips (including Intel x86 processors, e.g.), but many different companies design ARM chips. This lets different companies tailor the design to specific use cases. Apple, for example, designs ARM processors that deliver a nice balance of performance and energy-efficiency for phones and laptops. Amazon has designed Graviton processors specifically for their cloud servers, and the latest generation Graviton3 is especially optimized for compute-intensive workloads. We launched Dask clusters on AWS using Intel, Graviton2, and Graviton3 processors to see how switching to ARM makes a difference.
Dask on Graviton2#
Previously, we used Dask and Coiled to process ~ 1TB of data to see how popular Matplotlib has been in scientific articles over the past decade. The dataset is publicly available in S3, saved as over 5,000 tar files, each of which contain a directory of articles. We extract each directory and do some minimal processing, which takes ~ 7 minutes with a 100-worker Coiled cluster.
We ran this workload 5 times on both x86-based t3 instances and ARM-based t4g instances and found, on average, a 30% cost reduction.
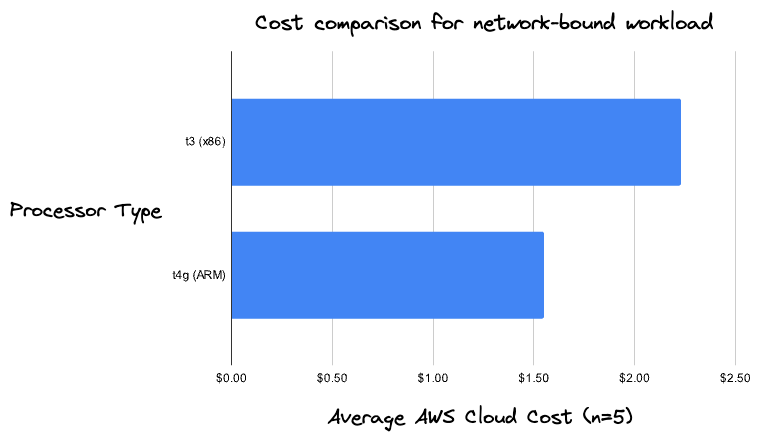
This workload doesn’t use much CPU or memory, and is instead primarily relying on network bandwidth. The general-purpose x86-based t3 and ARM-based t4g instance types are a good fit for this type of workload, since they are readily available and provide more than enough performance without additional charges.
To see how robust these results were across a variety of workloads, we also ran a number of benchmarks for common Dask Array and Dask DataFrame operations. Across 19 different benchmarks, the ARM-based t4g instances were reliably cheaper for all but one, where there was a 2.3% cost increase. Cost savings were around 30% averaging across all tests, ranging from 15-55%.
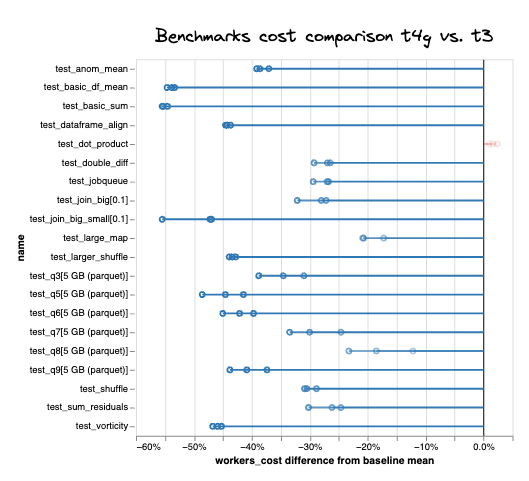
Percent difference in estimated AWS costs for t4g (ARM-based) vs. t3 workers (x86-based)#
On the high end, test_vorticity, for example, was 46% cheaper (on average across three trials). This test is a simplification of a Dask Array operation commonly used in geoscience workloads and is primarily compute-bound.
Dask on Graviton3#
In February, AWS launched additional general-purpose Graviton3-based instance types, the m7g, with reportedly up to 25% better performance than their predecessors. For more details on Graviton3 performance improvements, we recommend this deep dive from Chips and Cheese.
We used XGBoost with Dask and Coiled to predict the trip duration for Uber and Lyft rides in NYC using the publicly available NYC Taxi dataset. In this workload we load the dataset, do some basic feature engineering, train and then cross-validate our XGBoost model. This takes ~5 minutes on a 45-worker Coiled cluster with 3 folds for cross-validation.
We ran this workload 5 times on both x86-based m6i instances and ARM-based m7g instances and found, on average, a 23% cost savings.
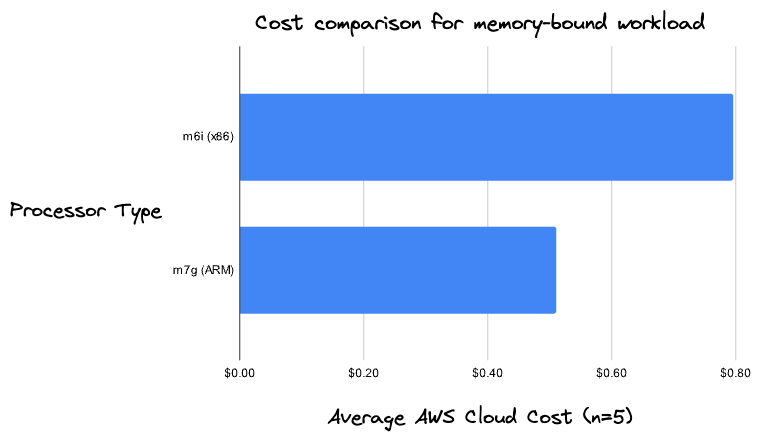
As opposed to the network-bound Matplotlib example, this workload is primarily computationally- and memory-bound, with total worker memory reaching just under 400 GB and workers reaching nearly 75% CPU utilization. For these types of workloads, instance type families that balance compute and memory are a good option.
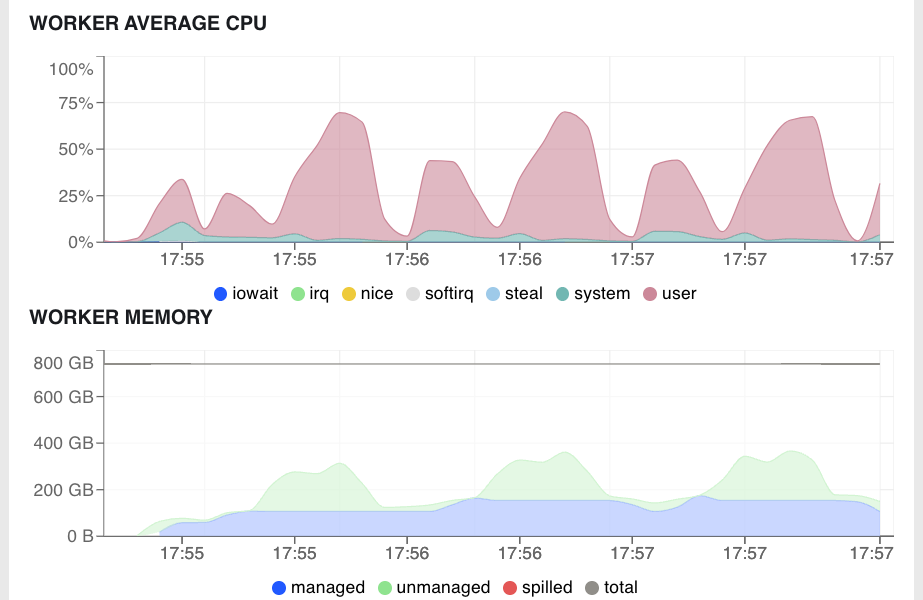
Average worker percent CPU utilization (top) and average worker memory (bottom) for XGBoost workload#
Again, to get a sense for how robust these cost savings are, we ran a the same benchmarks as above comparing m6i and m7g instance types. Across the 19 different benchmarks, the ARM-based m7g instances were reliably cheaper for all but three, where ARM was, at most 25% more expensive. Where ARM was cheaper, estimated cost savings ranged from 5-55%, with an average of ~ 20% cost savings across tests.
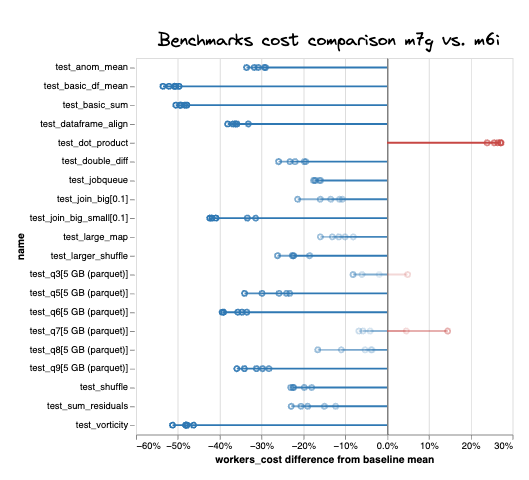
Percent difference in estimated AWS costs for m7g (ARM-based) vs. m6i workers (x86-based)#
Focusing again at the primarily compute-bound test_vorticity, m7g workers were 48% cheaper than using a cluster with m6i workers.
Using ARM with Coiled#
Graviton processors are designed by Amazon specifically with cloud performance in mind and they consume far less energy. So why not try them for your own workloads? One challenge is ensuring your compiled dependencies are ARM-compatible. In many cases, the dependencies you’ll need are prebuilt for both x86 and ARM. If you’re using custom dependencies or an older version of a library, however, you may run into issues.
As of Coiled version 0.6.0, your local Python environment will be replicated on your cluster, including any necessary platform-specific dependencies, making it easy to create a cluster with ARM-based instances.
cluster = coiled.Cluster(
# ARM instance types for scheduler and workers
arm=True,
n_workers=10,
)
You can see for yourself whether switching to ARM-based clusters saves on AWS costs or improves performance (see our documentation for more details). Try it out and let us know how it goes!
If you’re not already using Coiled, it’s free to try out and easy to get started.