Filestores#
Filestores are cloud storage volumes. Filestores provide an easy way to:
Copy data between your local machine and Coiled-managed VMs in the cloud,
Persist data between multiple runs, or
Transfer data between steps in a processing pipeline.
With Coiled Batch#
Sync Files#
Filestores are available in the coiled batch run API:
coiled batch run --sync local-directory my_script.py
This will use a filestore to copy local files from local-directory to the cloud VM where my_script.py is run. The files will be available in the working directory.
Any outputs that your code writes to the working directory on the cloud VM will be stored in a filestore, available for download to your local machine or to other Coiled-managed cloud VMs.
Because the default behavior for coiled batch run is to submit work to Coiled without blocking locally, it won’t, by default, sync files from the run back to your local machine when done. If you’d like to have the local client wait until work is done, and then sync files back to your local machine, you can do this with --wait:
coiled batch run --sync local-directory --wait my_script.py
Files in local-directory will now be copied to the working directory where my_script.py runs in the cloud, and when this batch job is complete, files written or modified in the working directory on the cloud VM(s) will be copied down to local-directory on your local machine.
All tasks in a batch job share the filestore. When using coiled batch run with multiple parallel tasks (i.e., --ntasks, --map-over-inputs, or one of the other ways of specifying parallelism), files synced from your local machine are available to all the tasks, and outputs from all the tasks can be synced back together to your local machine.
Separate Upload and/or Download#
You can also use distinct local directories for each direction:
coiled batch run \
--upload input-directory \
--download output-directory \
--wait \
my_script.py \
If you only want to copy files in one direction—local inputs to cloud VM, or outputs from cloud VM to local—then you can use --upload or --download individually.
Capture Text to Filestore#
For scripts that output directly to the terminal, you can automatically capture that output to files in a filestore.
coiled batch run --pipe-to-files --download output-directory --wait \
echo Hello
This will capture both standard error (in this case empty) and standard out (“Hello”) as files:
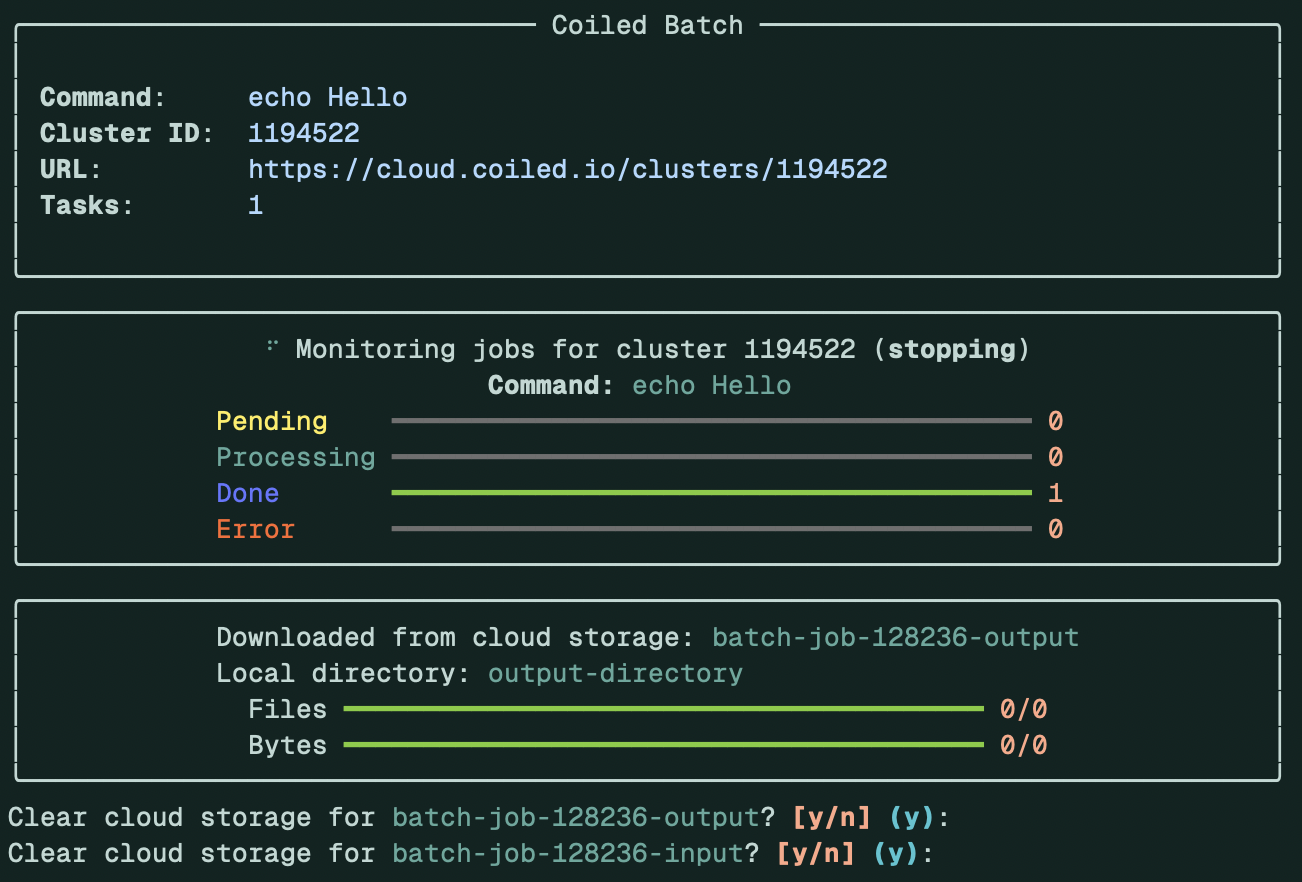
$ tree output-directory
output-directory
└── output
└── 0
├── task-0-stderr.txt
└── task-0-stdout.txt
2 directories, 2 files
$ cat output-directory/output/0/task-0-stdout.txt
Hello
Other Ways of Using Filestores#
Above, we said that filestores are cloud storage volumes. This is a useful but not entirely accurate mental model.
When you run coiled batch run --sync, Coiled creates two filestores:
an input filestore for copying files to the cloud VM(s), and
an output filestore for copying files from the cloud VM(s).
By default, coiled batch run --sync creates two new filestores each time you run it.
Multiple runs with the same input data#
To use the same input filestore for multiple runs, without re-uploading the files for each run, use --input-filestore to give the filestore a name:
coiled batch run \
--input-filestore my-named-fs \
--upload local-directory \
...
When you run this the first time, the named filestore will be created. When you run this again, that same filestore will be re-used (assuming you’re creating cloud VMs in the same region). Files that are already in the filestore and haven’t been modified since they were first uploaded won’t be uploaded again.
Pipeline of Runs#
To use the outputs from one batch job as the inputs to another, without needed to download and re-upload the files, use the same filestore:
coiled batch run --output-filestore step-1-fs ...
# wait until the above run is complete
coiled batch run --intput-filestore step-1-fs ...
Persistent Storage for Repeated Runs#
To have persistent storage so that any files modified or added by one run are available to the next, attach a single filestore as both input and output:
coiled batch run --input-filestore my-fs --output-filestore my-fs ...
As a toy example, you could have each run write a file that says how many run files there are at that time:
echo "There are $(ls -1 *-status.txt 2> /dev/null | wc -l | tr -d ' ') status files at $(date +%s)" \
| tee "$(date +%s)-status.txt"
Each time you run this with the same input and output filestores, it will add a new file that says how many times it has been run before.
Take a look at our example of running MLflow on Coiled for a more realistic use case.
How Does This Work?#
Filestores are built on top of blob storage: S3 (AWS), GCS (Google Cloud), and Storage Account Containers (Azure).
Note
Only AWS is currently supported, but we plan to support other cloud providers soon—please let us know if this is important to you.
Filestores require additional permissions so that Coiled can read from and write to specific buckets. Coiled does not have access to other data in your account, just the designated buckets used for filestores.
On AWS, these permissions allow access to S3 buckets with coiled-data- as the first part of the name. The exact permissions are:
{
"Sid": "OngoingPersistentDataBuckets",
"Effect": "Allow",
"Action": [
"s3:CreateBucket",
"s3:ListBucket",
"s3:PutBucketOwnershipControls",
"s3:PutBucketPolicy"
],
"Resource": ["arn:*:s3:::coiled-data-*"]
},
{
"Sid": "OngoingPersistentDataObjects",
"Effect": "Allow",
"Action": [
"s3:PutObject",
"s3:GetObject",
],
"Resource": ["arn:*:s3:::coiled-data-*/*"]
}
Existing Coiled workspaces may not already have these permissions. If you want to use filestores with an existing workspace, you can re-run the cloud provider setup for the workspace. (It’s also possible to manually add the permissions—let us know if you’d like help with this.)
Coiled will automatically create buckets per-region as needed. Bucket names are obfuscated and do not include any identifying information about your workspace, as S3 bucket names are not secret (AWS automatically creates a public DNS record for each S3 bucket).
Coiled uses a single bucket for all filestores for a given Coiled workspace in a given region. The buckets are regional to avoid cross-region traffic costs.
The buckets are private, so only those with permission can list or access files in these buckets. When copying files to or from a filestore, the Coiled control-plane generates signed URLs and provides these to the local client or to our agent running on the Coiled-managed VMs.