Posted in 2023
Processing Terabyte-Scale NASA Cloud Datasets with Coiled
- 01 November 2023
We show how to run existing NASA data workflows on the cloud, in parallel, with minimal code changes using Coiled. We also discuss cost optimization.

TPC-H Benchmarks for Query Optimization with Dask Expressions
- 05 October 2023
Dask-expr is an ongoing effort to add a logical query optimization layer to Dask DataFrames. We now have the first benchmark results to share that were run against the current DataFrame implementation.
Coiled observability wins: Chunksize
- 19 September 2023
Distributed computing is hard, distributed debugging is even harder. Dask tries to simplify this process as much as possible. Coiled adds additional observability features for your Dask clusters and processes them to help users understand their workflows better.

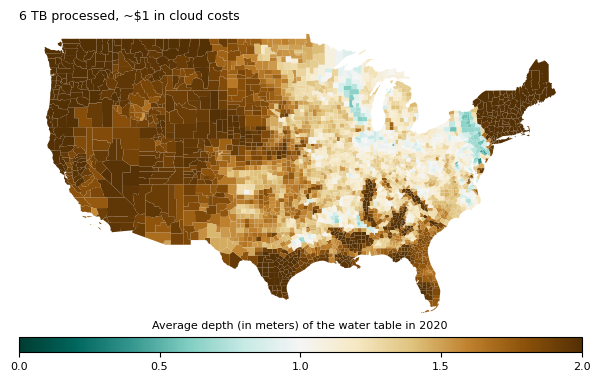
Processing a 250 TB dataset with Coiled, Dask, and Xarray
- 05 September 2023
We processed 250TB of geospatial cloud data in twenty minutes on the cloud with Xarray, Dask, and Coiled. We do this to demonstrate scale and to think about costs.
Reduce training time for CPU intensive models with scikit-learn and Coiled Functions
- 01 September 2023
Sep 1, 2023
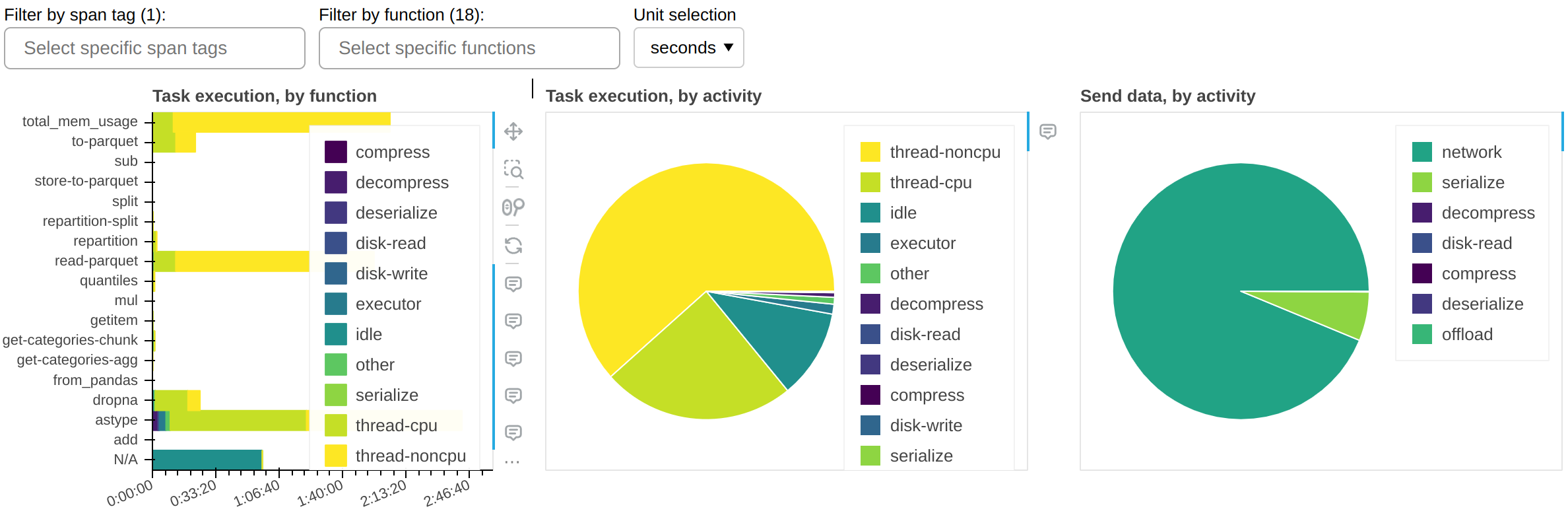
Fine Performance Metrics and Spans
- 23 August 2023
While it’s trivial to measure the end-to-end runtime of a Dask workload, the next logical step - breaking down this time to understand if it could be faster - has historically been a much more arduous task that required a lot of intuition and legwork, for novice and expert users alike. We wanted to change that.
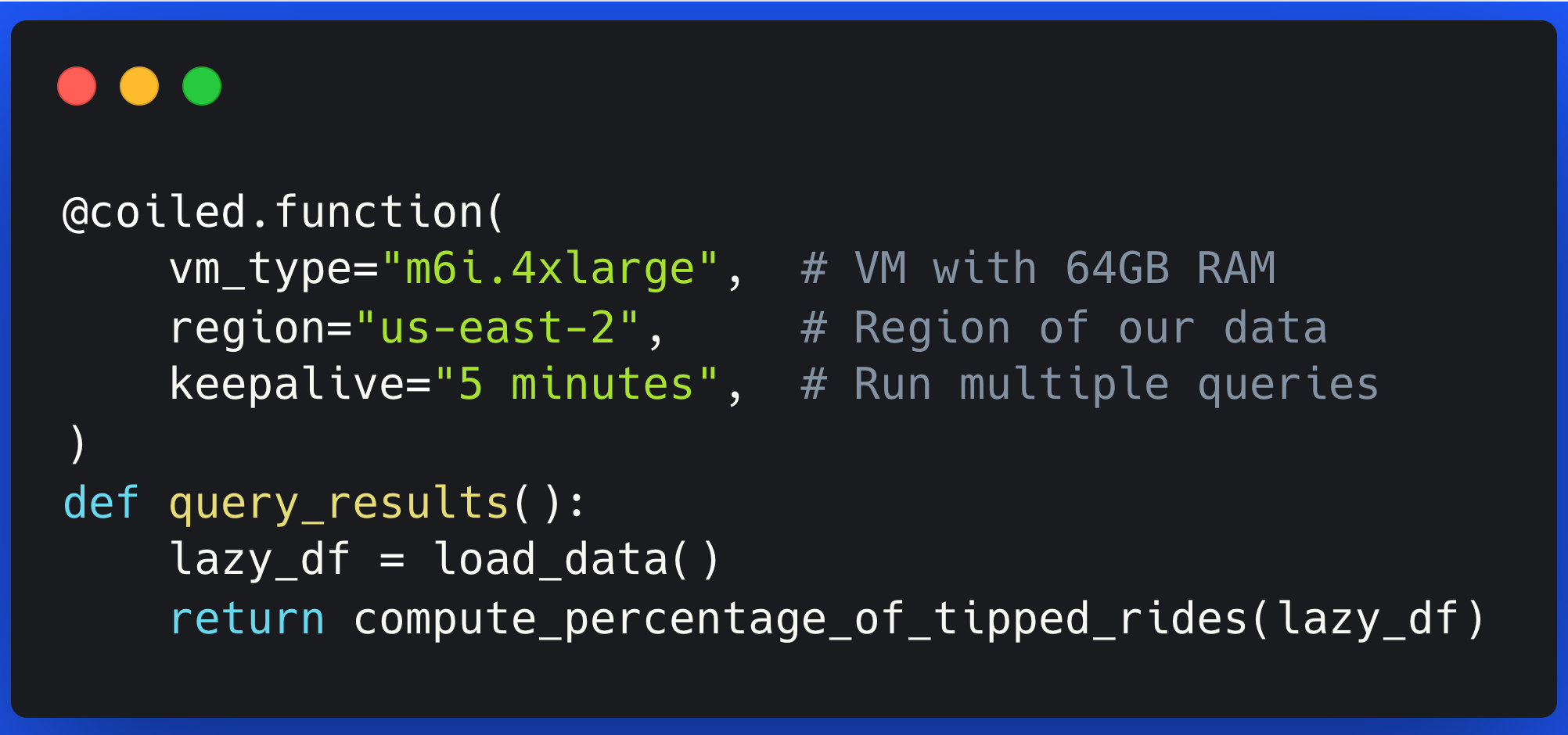
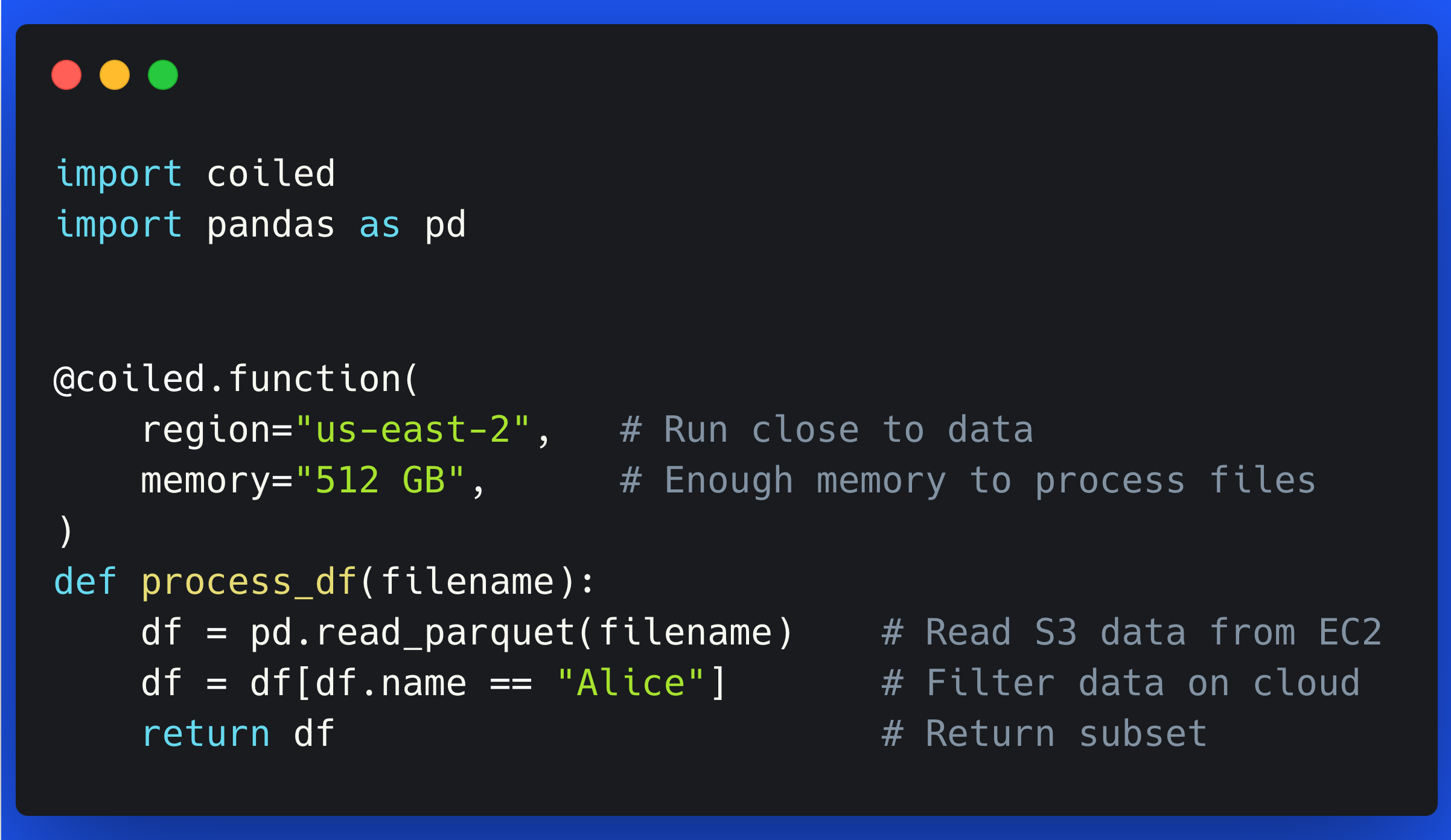
Data-proximate Computing with Coiled Functions
- 10 August 2023
Coiled Functions make it easy to improve performance and reduce costs by moving your computations next to your cloud data.
Dask, Dagster, and Coiled for Production Analysis at OnlineApp
- 09 August 2023
We show a simple integration between Dagster and Dask+Coiled. We discuss how this made a common problem, processing a large set of files every month, really easy.

High Level Query Optimization in Dask
- 04 August 2023
Dask DataFrame doesn’t currently optimize your code for you (like Spark or a SQL database would). This means that users waste a lot of computation. Let’s look at a common example which looks ok at first glance, but is actually pretty inefficient.
Easy Heavyweight Serverless Functions
- 01 August 2023
What is the easiest way to run Python code in the cloud, especially for compute jobs?
Coiled notebooks
- 14 June 2023
We recently pushed out a new, experimental notebooks feature for easily launching Jupyter servers in the cloud from your local machine. We’re excited about Coiled notebooks because they:
Distributed printing
- 18 May 2023
Dask makes it easy to print whether you’re running code locally on your laptop, or remotely on a cluster in the cloud.
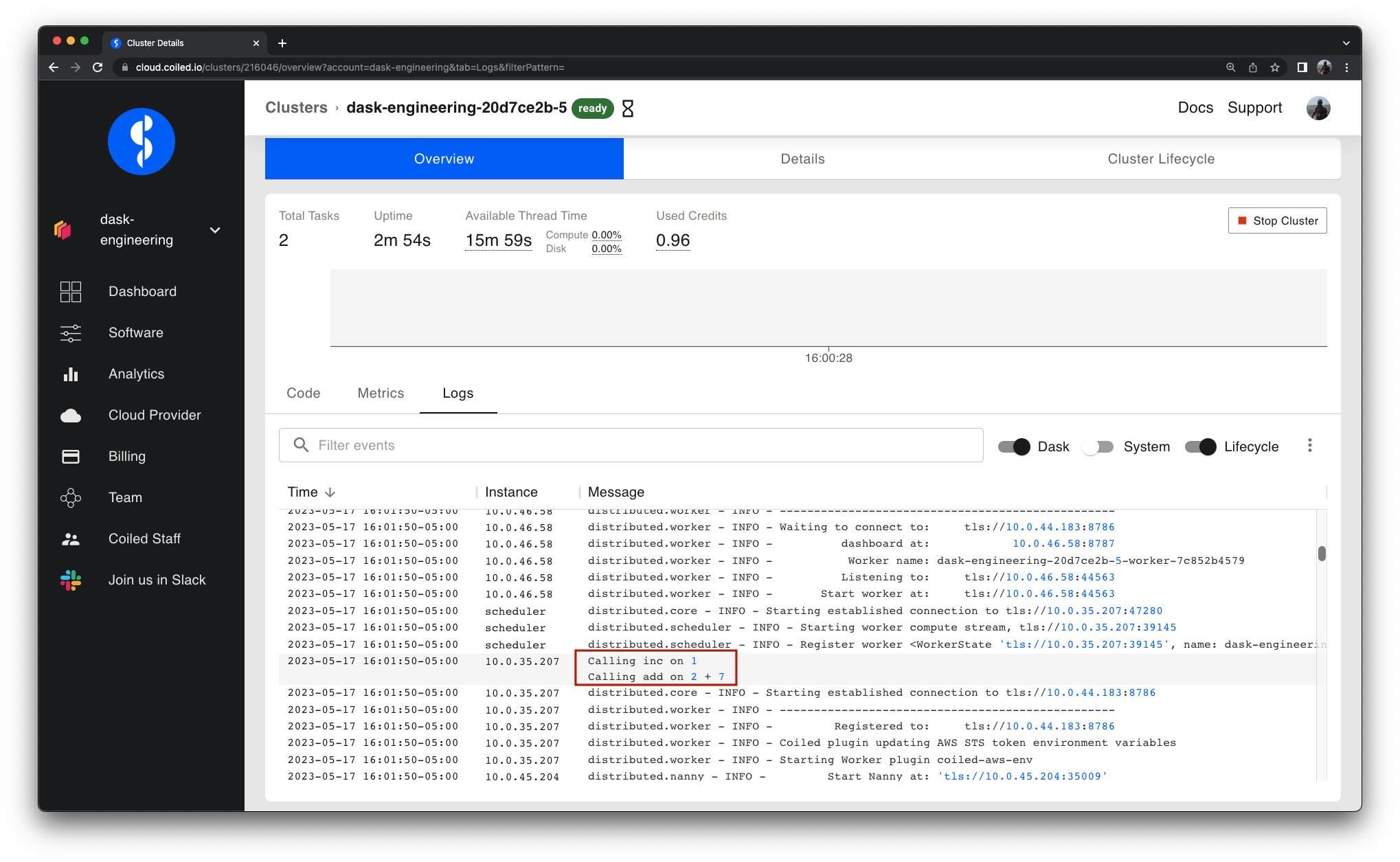
Performance testing at Coiled
- 05 May 2023
At Coiled we develop Dask and automatically deploy it to large clusters of cloud workers (sometimes 1000+ EC2 instances at once!). In order to avoid surprises when we publish a new release, Dask needs to be covered by a comprehensive battery of tests — both for functionality and performance.
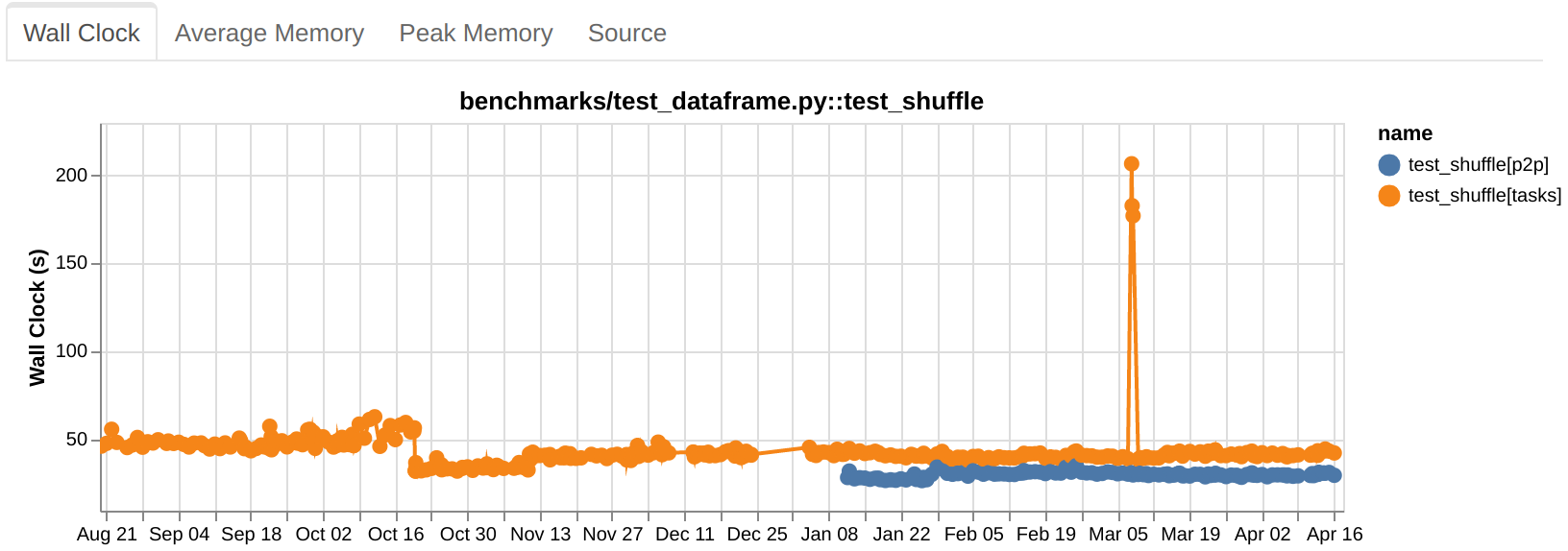
Upstream testing in Dask
- 18 April 2023
Dask has deep integrations with other libraries in the PyData ecosystem like NumPy, pandas, Zarr, PyArrow, and more. Part of providing a good experience for Dask users is making sure that Dask continues to work well with this community of libraries as they push out new releases. This post walks through how Dask maintainers proactively ensure Dask continuously works with its surrounding ecosystem.
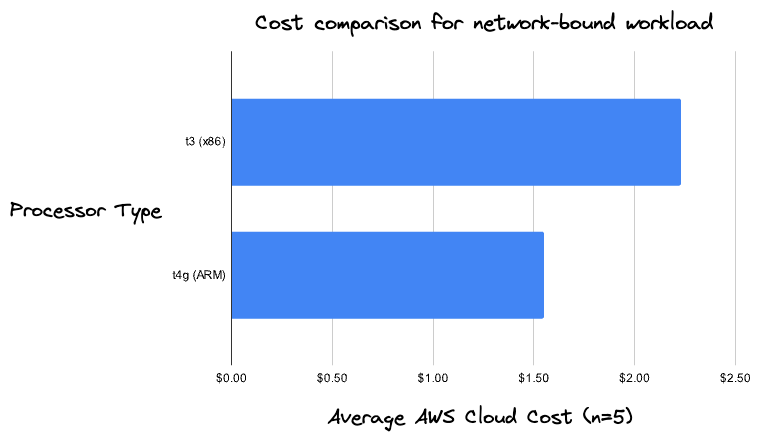
Burstable vs non-burstable AWS instance types for data engineering workloads
- 04 April 2023
Apr 4, 2023

How many PEPs does it take to install a package?
- 17 January 2023
A few months ago we released package sync, a feature that takes your Python environment and replicates it in the cloud with zero effort.
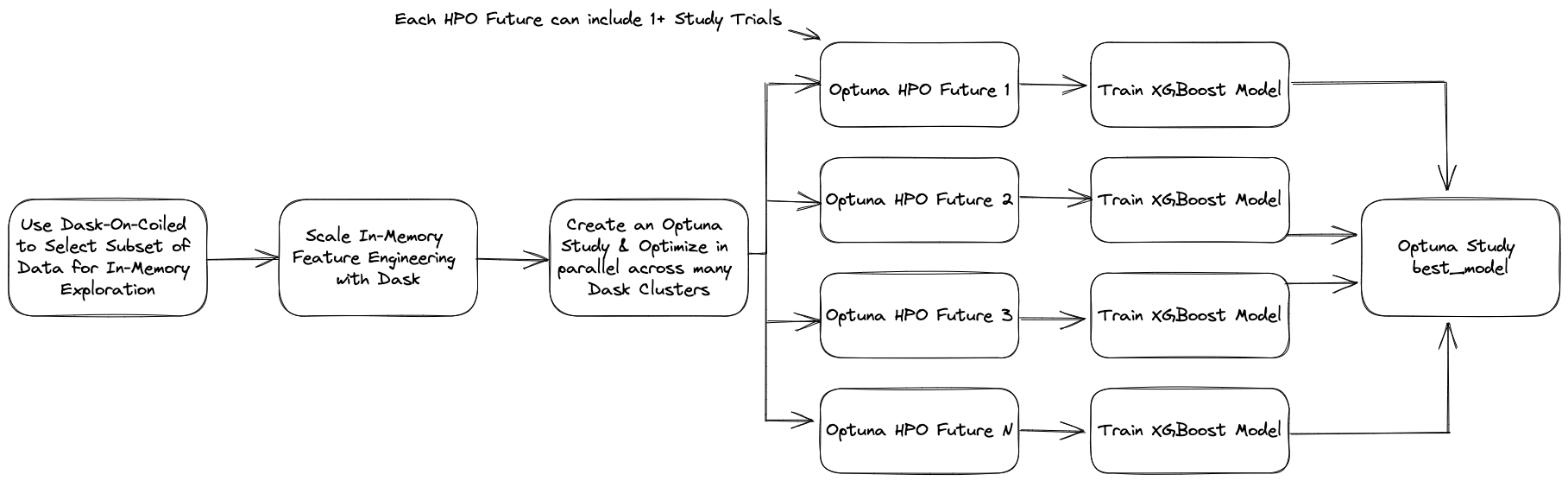
Scaling Hyperparameter Optimization With XGBoost, Optuna, and Dask
- 06 January 2023
XGBoost is one of the most well-known libraries among data scientists, having become one of the top choices among Kaggle competitors. It is performant in a wide of array of supervised machine learning problems, implements scalable training through the rabit library, and integrates with many big data processing tools, including Dask.
Handling Unexpected AWS IAM Changes
- 06 January 2023
The cloud is tricky! You might think the rules that determine which IAM permissions are required for which actions will continue to apply in the same way. You might think they’d apply the same way to different AWS accounts. Or that if these things aren’t true, at least AWS will let you know. (I did.) You’d be wrong!