Schedule Python Jobs with Prefect and Coiled¶
Prefect is a popular workflow management system. Its intuitive API makes writing workflows straightforward, especially for Python developers, who can usually start running on their laptop in just a few minutes.
It’s common to want to run a workflow, or specific task within a workflow, on a VM in the cloud instead of locally for different reasons:
You want an always-on machine for long-running, or regularly scheduled, jobs
You want to run close to your cloud-hosted data
You want specific hardware (e.g. GPU, lots of memory)
You want many machines for running tasks in parallel
This post shows how to deploy a Prefect workflow on the cloud using Coiled. The workflow runs a regularly scheduled job on a dataset that’s updated daily. While the real-world example we show in this post highlights a geospatial use case, the overall pattern of running regularly scheduled jobs is common in many fields (e.g. machine learning, finance, remote sensing, sports betting, etc.) and looks something like the following:
import coiled
from prefect import flow, task
# Step 1: Find new data files to be processed.
@task
def get_new_data_files():
files = ...
return files
# Step 2: Process input data file.
# This often requires specific computing resources.
@task
@coiled.function(...)
def process(file):
results = ...
return results
# Step 3: Combine tasks into a full workflow that
# processes all new data files.
@flow
def workflow():
files = get_new_data_files()
futures = process.map(files)
for future in futures:
print(f"Saved file {future.result()}")
# Step 4: Run the workflow on some regular cadence.
if __name__ == "__main__":
workflow.serve(interval=...)
Workflow¶
Each day NASA satellites collect sea surface temperature measurements that are then processed and stored in a new file added to the Global Sea Surface Temperature dataset on AWS S3. Our workflow consists of a daily job that finds the newly added file, does additional processing on that data, and saves the processed result to an S3 bucket.
Following the pattern above we have:
# workflow.py
import datetime
import os
import tempfile
import coiled
import earthaccess
import numpy as np
import s3fs
import xarray as xr
from prefect import flow, task
IN_BUCKET = "s3://podaac-ops-cumulus-protected/MUR-JPL-L4-GLOB-v4.1"
OUT_BUCKET = "s3://openscapes-scratch/MUR-SST"
# Step 1: Find new data files to be processed.
@task
def get_new_data_files() -> set[str]:
# Get all files from data source bucket and output destination bucket
fs_in = earthaccess.get_s3fs_session(provider="POCLOUD")
infiles = set(map(os.path.basename, fs_in.glob(IN_BUCKET + "/*.nc")))
fs_out = s3fs.S3FileSystem()
outfiles = set(map(os.path.basename, fs_out.glob(OUT_BUCKET + "/*.nc")))
# Find new files that haven't been processed yet
return infiles - outfiles
# Step 2: Process input data file.
# We run this task on a VM in the same region as the data
# that's large enough to reliably process files.
@task
@coiled.function(
region="us-west-2", # Same region as data
vm_type="m6i.large", # Big enough VM to process data
)
def process(file: str) -> str:
# Open file with `xarray`
fs_in = earthaccess.get_s3fs_session(provider="POCLOUD")
ds = xr.open_dataset(fs_in.open(IN_BUCKET + f"/{file}"))
# Select specific region of interest + data validation
ds = ds.sel(lon=slice(-93, -76), lat=slice(41, 49))
cond = (ds.sea_ice_fraction < 0.15) | np.isnan(ds.sea_ice_fraction)
result = ds.analysed_sst.where(cond)
# Save processed result to S3
with tempfile.TemporaryDirectory() as tmpdir:
local_file = os.path.join(tmpdir, file)
result.to_netcdf(local_file)
fs_out = s3fs.S3FileSystem()
outfile = OUT_BUCKET + f"/{file}"
fs_out.put(local_file, outfile)
return outfile
# Step 3: Combine tasks into a full workflow that
# processes all new data files.
@flow
def workflow():
files = get_new_data_files()
futures = process.map(files)
for future in futures:
print(f"Saved file {future.result()}")
# Step 4: Run the workflow once a day.
if __name__ == "__main__":
workflow.serve(name="NASA-SST", interval=datetime.timedelta(days=1))
There are a couple of key points to highlight:
We lightly annotate our
processfunction with the@coiled.functiondecorator to have it run on a separate cloud VM with enough resources to process our data files. We also make sure the functions runs in the same region where our data is to avoid data transfer costs:@task @coiled.function( region="us-west-2", # Same region as data vm_type="m6i.large", # Big enough VM to process data ) def process(file: str) -> str: ...
See Coiled Functions to learn more about using serverless functions.
Since our dataset is updated once a day, we set the workflow’s
interval=to automatically run daily.workflow.serve(name="NASA-SST", interval=datetime.timedelta(days=1))
Deploy on the cloud¶
With our workflow ready to go, we now deploy it to an always-on cloud VM using the coiled prefect serve CLI:
coiled prefect serve \ # Run on the cloud
--region us-west-2 \ # Same region as data
--vm-type t3.medium \ # Cheap always-on VM for serving the workflow
-e AWS_ACCESS_KEY_ID="..." \ # AWS credentials to write to output bucket
-e AWS_SECRET_ACCESS_KEY="..." \
-e EARTHDATA_USERNAME="..." \ # Earthdata credentials to read NASA data bucket
-e EARTHDATA_PASSWORD="..." \
workflow.py
Because our resource-heavy process function is dispatched to a separate VM using Coiled Functions, the rest of the workflow doesn’t need significant computing resources and can be run on a small, inexpensive t3.medium instance (costs ~$0.04/hr or less than a dollar a day). We also include two sets of secrets, one for reading data from the NASA bucket and one for writing to our processed data bucket, using the -e option for securely setting environment variables secrets.
Now once a day an m6i.large instance is spun up to run our process function on a new data file and then automatically spun down.
We can see our flow running in both Coiled and Prefect:
Coiled Workflow running in Coiled UI.¶
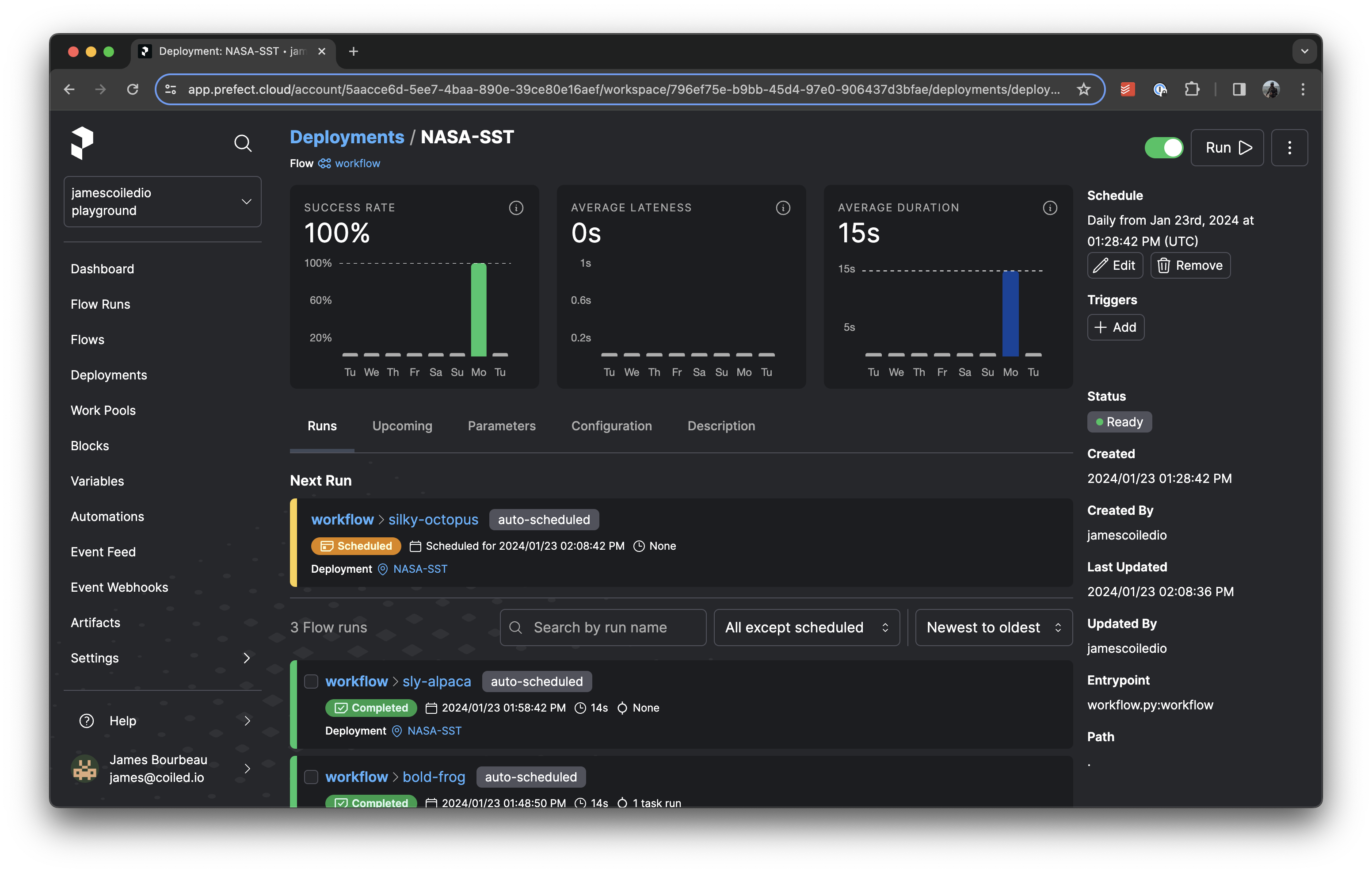
Workflow running in Prefect UI.¶
Summary¶
We ran a common example of a regularly scheduled job on the cloud using Prefect and Coiled. This was:
Easy: Minimal code changes were needed to run Prefect code on the cloud.
Cheap: Costs ~$1/day to run.
We hope this post shows that with just a handful of lines of code you can run your Prefect workflows on the cloud. We also hope it provides a template you can copy and adapt for your own use case.
Want to run this example yourself?
Get started with Coiled for free at coiled.io/start. This example runs comfortably within the free tier.
Run the code snippet above.